1. DATABASES• Basically databases are used to store information. • A primitive form of ‘database’ is a filing cabinet. • The fundamental types of databases include, - Relational - Data is kept in fixed tables with defined relationships - Object Oriented - Dissimilar data can be stored in a single list (relational databases are a sort of subset of these databases) • Databases allow information stored on one computer to be shared with other computers. • Data stored in relational databases is commonly access using SQL (Structured Query Language) • Databases handle problems of, - data locking (only allow one user to modify at once) - data sharing (other users can view) MESSAGE PASSING ON NETWORKSInterprocess Communication with the MPS (Message Passing System) The University of Western Ontario Keywords: Distributed Processing, Concurrent, Interprocess Communication, Message Passing, Course Grain, Asynchronous, Client-Server, Heterogenous, Network An asynchronous message passing system has been developed to allow integration of many dissimilar tasks. In particular, the tasks run on a number of different hardware platforms, using a number of different software packages and languages. The system is based on a single server which handles communication between all clients. A new concept of groups and priorities is used to organize message flow. This structure also allows clients to sign on and off in an ad-hoc manner while isolating disturbances to other clients. The groups and priorities concept makes it possible to explicitly define a number of concurrent and parallel execution methods. Thus, the method described in this paper addresses the needs for integrating tasks in a typical computing environment. The Message Passing System (MPS) is intended to simplify communication between more than two programs. The programs may be resident on many computers, and are not necessarily written in C or for a UNIX machine. In real terms, the MPS communication structure can be seen in Figure 1 below. The normal method of communication is also shown below. 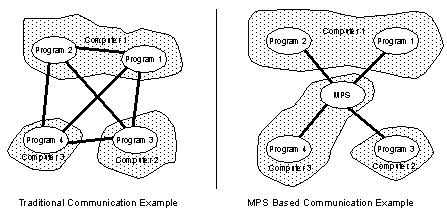
Figure 1 - An Example of Network Based Interprocess Communications While the traditional method lends itself to speed, it requires that each program have sophisticated functions for communication and an interface to each of the other programs. The MPS scheme allows the sophisticated functions to be present in only the central server (i.e., MPS), and the same interface subroutines to be reused for each program. The MPS system has been developed with a number of idealized objectives. When the system was developed, most of the objectives were met (or will be in the near future). The list below summarizes the objectives. - Near real time response, in the range of one second or less. (This approach is not intended to compete with real-time systems). - Buffering of messages between processes. - General knowledge of processes, but no specifics, or direct access to remote data. - Maintenance major methods of concurrent and distributed processing. - Allows insertion into communication loop for testing analysis, and other processes. - Allows message broadcast to unknown program. - Keeps running record of transactions for forensics, and restarting, in case of failure. - Does not try to replace existing communication methods, but allows coexistence. - Independant of machine type, language used, and the details of the network. The objectives above also double as advantages. But, as a result of these functional requirements, we were forced to use a central server for the system. Otherwise, a decision to incorporate these functions into each program would have been a very difficult (if not impossible) task. The decision to use a central communication server is not ideal. Using a central server builds a bottleneck into the system. It means that only one program may be served at once, and the speed of the server will limit the communication rate. Alternately, if each program was to have its own interface, the programs could communicate simultaneously, and only be limited by their own speeds, and network transmission delays. This paper will first attempt to put the work in perspective, and then will develop the MPS model by explaining each feature individually. 1.2 A Short Note on Concurrent and Parallel Processes There are two approaches to splitting up large programming problems; concurrently and parallelism. The major difference between the approaches is in how they divide problems. Concurrent solutions involve many similar processes performing the same operation. In parallel solutions various processes are used to solve different parts of a problem. An example of a concurrent solution to a problem is using a secretarial pool to have each secretary type one chapter of a book, concurrently. An example of a parallel solution to a problem is to give one copy of the book to a fact checker, and another to a proof reader, so that they may work in parallel. The use of parallel and concurrent solutions should be viewed as complementary approaches. In the MPS, concurrency is automatic when two or more clients with the same group and priority are run. Parallelism is established by groups, with various functions performed by each group. It is up to the user to determine how the programming problem can be split up and coordinated. Standard programming methods have focussed on sequential programming techniques. This is understandable because of the ease of hardware design, and the appeal of linear logic to the programmer. As computers become more popular as a tool, the bottleneck of a single instruction stream becomes more critical. Thus, researchers began to examine computing with multiple instruction and data streams [Sikorski, 1991]. In particular computing with multiple instruction streams has become very interesting. Researchers have tended to split into two sections, those which develop multi-processor computers for single large problems, and networked computers for multiple and distributable problems. At present many computers are connected by networks on a world wide scale. The enormous potential for computing power makes the value of the network obvious, but without the proper programming techniques the power is lost. When discussing a concurrent process (distributed on two or more computers), there are two main branches of discussion. In a tightly coupled system the processes use a technique such as shared memory. In a loosely coupled system message passing is used. Passing information and requests by messages allows isolation between processes which might have interaction problems, but this often results in more complex hardware. When message passing, the messages may be characterized in the form [Andrews, 1991], - synchronous (good for real time systems) Each of these has various merits, but in particular the asynchronous methods have great advantage. These were the only methods that would make it easy to cut the connections between two processes. There are many methods which use asynchronous message passing, but the majority are in languages such as Actors [Agha et. al., 1987], and NIL [Strom et. al., 1983]. The language approach has some inherent problems with the flow of control. The entire concurrent system needs one start point, and will not tolerate two competing main programs, such as user interfaces. This also poses a greater problem when a process is started or stopped during the system execution. The largest advantage to the language based approach is speed, ease of use for one task, and reliability (excluding faults). This may readily be seen in work by Buhr et. al. [1991], Otto [1991], Grimshaw [1991], and Birman [1991]. These researchers use a variety of techniques for programming and communication, but essentially provide embedded tools for distribution and parallelization. Another interesting approach was developed by Singh et. al. [1991] in their Frameworks system. Although their system is based on an RPC method they allow a user to write fairly independant tasks, then fit them together with a graphical tool. The interesting part of their system was a process group structure, which treated all processes as concurrent or non-concurrent, and allowed input and output conditions to be defined. If the reader looks beyond the superficial differences, they will see an underlying philosophy which is common between their work, and the work presented here. During development of the workcell controller in 1990 (By H.Jack) it was discovered that the control of the workcell was difficult to do with a single program. This set the tone for exploring concurrent programs and communication. The first attempts were done with files, with a degree of success. This approach was basically a file driven semaphore system [Jack and Buchal, 1992]. This had weaknesses, and depended heavily on a common disk. Also, the communications were very slow, difficult to implement, and hard to change. As a result, other methods, like sockets, were examined for networked communication. It was decided that these had many of the same problems of the file transfer mechanism. The concept of MPS was developed in a crude form in the late summer of 1990. A crude implementation of MPS was developed in early 1991. This version only had simple communication. After proof of this implementation it was discussed with other researchers. It was discovered that it would have applications to the CAPP project (described in Section 6), in addition to the original Workcell control. The MPS model was improved, and implementation continued in the workcell. At the same time Jimmy Chien was examining the use of the MPS for the CAPP project, along with Hugh Jack. Some of the issues raised by the CAPP project helped bring depth to the MPS implementation. By the Fall of 1991 the MPS system had been fully developed, and had been used in a ray tracing application, and the workcell controller. These implementations were both successful, and lead to the evolution of the MPS model. Another Ray Tracing Application was done by Patrick Surry, when he tied ACIS, and PV-Ray together. He again exposed some short falls in the system, and new features were added. By this time the system was well developed, although some features were (and are) still in planning stages. This moves to the final application of the MPS to the CAPP/PPC Integration project. The were three competing methods presented for the integration of CAPP and PPC. Two methods were based on using message passing systems which utilize databases (one relational, and the other object-oriented), and the third method used the MPS. The original project decision was to pursue the use of an existing Oracle Database message passing system provided by the German team from IPA, Stutgart, Germany. After some time in development the problems involved with using Oracle became obvious, and MPS was selected as the method event transfer between CAPP and PPC. This was encouraging from the perspective that the MPS was originally intended for control only, but was so appealing that it replaced an existing (and proven) approach to handle events. The future of this software is that it will be developed to be one of the primary mechanisms in systems development for a new Design Engine Being developed at UWO, as part of a Strategic NSREC Grant. 2.0 The MPS Model of Interprocess Connection The actual connections between programs is of little importance in the MPS approach, therefore the reader should ignore it. The graph below contains an example of interprocess communication based on an MPS approach. 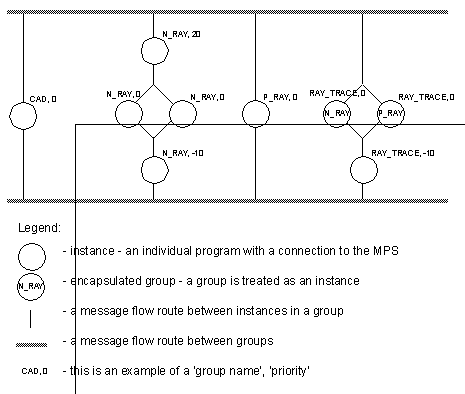
Figure 2 - An Example of an MPS Graph for CAD Driven Ray Tracing Each instance (a program connected to the MPS) belongs to a group. And, within the group each instance has a priority. For example, Figure 2 shows four groups, one of which is ‘N_RAY’. In the group ‘N_RAY’ there are four instances, one at priority 20, two at priority 0, and one at priority -10. Therefore, when a message is passed to this group, the priority 20 client will be the first to receive it. This client may pass the message unchanged, or change it, or not pass it at all. If any message comes out of ‘N_RAY, 20’, then it will be available for pickup by ‘N_RAY,0’. Since two programs have the same identification, they are concurrent, and either one can pick up the message (on a first come first served basis). A message written out by either ‘N_RAY,0’ will then go to ‘N_RAY,-10’. After a message leaves ‘N_RAY,-10’ it will be free to be passed to another group. Each message is given a source and destination group as it travels through the graph (and will always have these, although they may be changed). This graph is updated and changes as new instances are initialized and deinitialized. For example, if ‘P_RAY,0’ has not been able to keep up with the demand, the user only needs to start the same program on another computer. There would now be two ‘P_RAY,0’ programs running, and processing. If the bottleneck goes away, either program may be stopped, and the MPS graph would again appear as in Figure 2. In Figure 3 an example program is shown which initializes itself as ‘N_RAY,0’, finds the reference number for the ‘CAD’ group, and then sends a message to it. The program then deinitializes from the MPS and exits. 
Figure 3 - An Instance ‘N_RAY,0’ Passes a Message to Group ‘CAD’ In the example above, the instance originates a message. In the example below, the instance ‘N_RAY,-10’ receives, alters and then passes the message along. 
Figure 4 - An Instance for Message Interception and Replacement of Message from ‘N_RAY,0’ (Note: Sleep() functions are used because such simple programs tend to overrun the MPS server with requests. The MPS has been able to serve from 5 to 100 requests a second depending upon platform and options used) The reader should note at this point that each message is an arbitrary combination of integer and string. Their use is entirely decided by the instances which receive and send them. The reader should also note that the message passing mechanism between groups is only one mode available. This will be discussed more in the following pages. Each instance must belong to a group, and have a priority. This determines when a message may be picked up by an instance. We encourage the use of a 0 level priority as the target in each group. By this it is implied that all instances with positive priorities act as preprocessors, and all instances with negative priorities act as post-processors. Moreover, the users are encouraged to leave divisions between priority numbers for easy insertion of new instances. This leads to a naturally modular system. 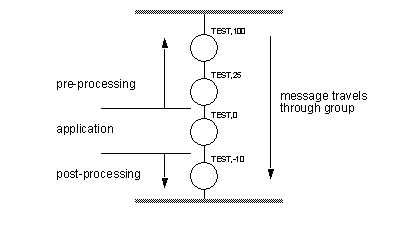
Figure 5 - An Example of Instances in a Group When two (or more) instances are run concurrently, they will receive and process messages as fast as possible. If the order of the message output from the concurrent instances does not have to match the order of message input, then there is no problem. In some cases instances it is necessary to maintain message sequence. Figure 6 illustrates the nature of this problem. 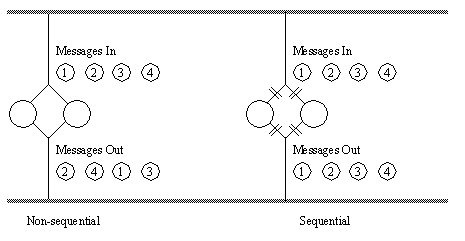
Figure 6 - The Problem of Sequence Preservation in Concurrent Processes If the user does not require a sequential concurrency, then they need not do anything. The default is for all instances to be considered non-sequential (as sequential instances are more expensive in terms of MPS computation). If an instance (being one of a ‘group, priority’) must be sequential, the user may turn this on as seen in Figure 7. 
Figure 7 - Example of An Instance Which Has Declared Itself Sequential (and by default, its concurrent neighbors). For this instance to be run concurrently, the user just runs multiple copies of the program. When a concurrent case is sequential, there are three events to consider. If one instance gets a message, and passes it on (by sending a message using “mb_send_message()”, then the MPS will keep the messages queued until it is their turn to be passed. This is transparent to the user. If the instance decides not to pass the message, then it must release the message so that it does not block the other waiting messages. This is also shown in Figure 7 above. There are three actions which may release a message: writing a message; reading a new message; releasing the message. The main reason for having a sequential concurrency is when the messages must be maintained in order for programs which are incapable of sorting order, or time based messages. An example of this is a robot driver which must receive messages in order, or the robot will make the right motions in the wrong order, and thus fail. 2.3 - Direct Instance Connection In some cases a message will have to pass directly between two instances. This has been allowed, although it violates the assumption that instances be ignorant of each other. As a compromise there have been three modes adopted, which are discussed below. 2.3.1 - General Broadcasts to All Instances In the most general mode, any instance can issue messages to every other client on the message board. The same message is issued to every client, and takes priority over messages passed between groups. An example of this is seen below in Figure 8. The message is read by each process in a normal manner (although messages directly to an instance are read before messages between groups). 
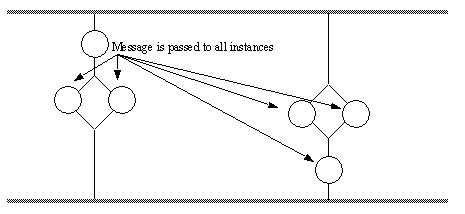
Figure 8 - An Immediate and General Broadcast of a Message to All Clients This approach is somewhat naive, and the messages may be sent to unexpected instances (except for the sending instance). 2.3.3 - General Broadcast of Messages to All Instances in a Group Another approach is to send the messages to all instances in a group. In this case the message travels normally until it approaches the first instance in the destination group (this mode is not immediate, and thus allows post-processing). Upon reaching the destination group, a copy is sent to each member of the group. These messages are immediate, and have a priority over messages passed between groups. Figure 9 shows one such example of sending a message of this type. 
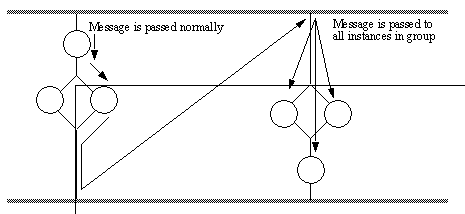
Figure 9 - A Broadcast to All Instances in a Group This method works well when a group does not contain messages. If a message is between instances in a group when this message arrives, then it may result in a conflict, or the message may be lost. For example, a message to kill all instances would result in the loss of a message which is still active. 2.3.3 - Sequential Broadcast of Messages to All Instances in a Group As described in the last section, when messages continue to flow through groups, the general broadcasts may not be desired. An alternative is to force the message to travel normally through the graph, but to be passed to all concurrent instances. This feature has not been implemented yet, but there are two cases which have been identified for implementation of this approach. In the illustration below, the two cases are shown comparatively (see Figure 10). The message is still addressed to a group, except that a message may be either blocking or non-blocking. 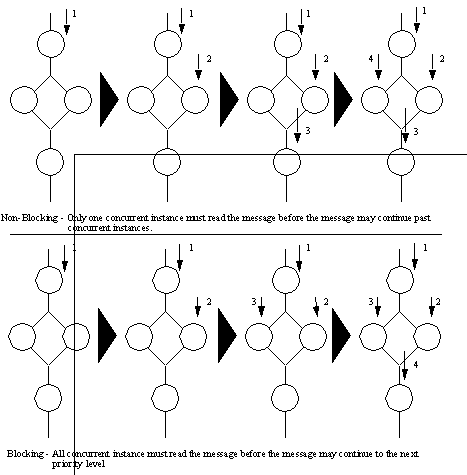
Figure 10 - An Example of Blocking and Non-blocking Broadcasts to all Instances in a Group (The message cannot be altered by any client in the group) As seen in Figure 10, blocking broadcasts force the message to wait until all concurrent instances have received the message before the next lower priority instance may receive it. In both cases the same message is passed to all instances, only the order of reception may vary (by the blocking/non-blocking constraints). Here, higher priority is guaranteed to see at least one copy of the message before lower priority, while “broadcast to all instances” doesn’t guarantee this. 2.3.4 - Direct Broadcast of a Message Between the Clients The last direct communication mode is the simplest to do. It mimics many existing methods. In this mode one instance sends a message directly to another instance. For this to happen, the sending instance must have a reference to the remote instance. This reference is a unique integer assigned to each instance. Each instance is only allowed to access its own instance number. Therefore, the sending instance must first get the destination instance number from the destination instance (Using normal group based communication techniques). While this is somewhat complicated, it ensures that integrity is maintained. (Note: An instance number is randomly assigned to each instance and therefore cannot be assumed to be the same between runs of a program.) Figure 11 below shows two programs which will perform a direct message pass. This is done after one gets the instance number of the other. 
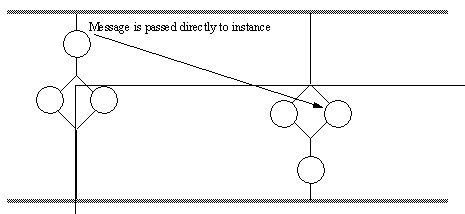
Figure 11 - Two programs which pass messages directly between each other (not via the MPS graph) 2.4 - Message Broadcasts To All Groups While section 2.3 outlined a number of approaches which address messages to instances, it did not discuss a method for splitting messages to all groups. If a message must be sent to unknown (or all) groups, a broadcast to all groups is ideal. The example in Figure 12 shows an application of this technique. 
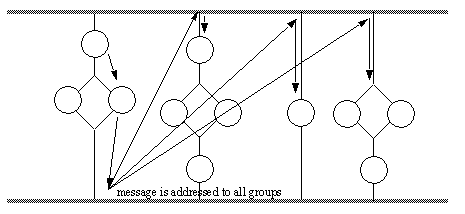
Figure 12 - A General Message Broadcast to All Groups The reader will note that the message passes normally through all instances as if an individual message has been passed to each group individually. An instance may decide to limit messages accepted by filtering its input. This ability has been provided by allowing the user to select a list of accepted groups. When an instance has created this list, it will call for messages. If the list is set to ‘ALL_GROUPS’, all messages will be accepted normally. If one or more groups are put on the filter list, messages from all other groups will be held until the ‘ALL_GROUPS’ filter status is set again. While the filter is in use, messages from selected groups will be passed normally, but the other messages will be queued up. When the filter is removed, all the queued messages will be available to be read. The example shown in Figure 13 shows a program which sets a filter, then clears it. 
Figure 13 - An Instance Which Sets and Clears a Group Based Message Filter The reader will find this feature useful when attempting to solve the mutual exclusion problem. This problem arises when two or more groups share a resource, but they must have exclusive use when they are accessing it. This feature makes it possible to set up a locking mechanism. The robot driver is an excellent example. While one group is using the robot, all other groups should be locked out. If two groups send a message to the robot at the same time, conflicting requests for motion are sure to happen. Thus, if one group is locked out, then the robot group will continue to receive a continuous and sensible stream of requests. While the groups in the MPS are vertically symmetrical, this is not always a desirable thing. The approach chosen to overcome this is to make it possible to encapsulate groups as an instance. If the reader refers back to Figure 2, they will notice that groups ‘N_RAY’ and ‘P_RAY’ are encapsulated in group ‘RAY_TRACE’. In this case the effect would be identical to replacing the instance with the group, as illustrated in Figure 14. 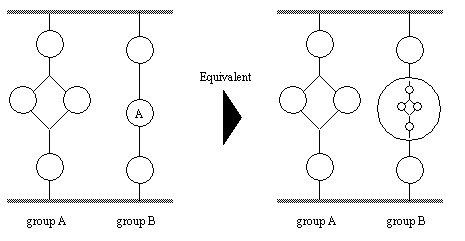
Figure 14 - Equivalent Representation of an Encapsulated Group Noting that group ‘A’ is still available for use, making this approach that much more versatile. In Figure 15 below, there is an example of how to declare an encapsulated group, assuming the group exists on the MPS graph. 
Figure 15 - A Coded Example of Declaring an Encapsulated Group The various general broadcasts will elicit different responses for encapsulated groups. If this is a general broadcast to members of a group, then the encapsulated group will be considered. In the case of a general broadcast to all instances, the encapsulated group instances will only receive one copy of the message. 3.0 Additional Features of MPS The centralization of MPS allows some features not normally available in distributed systems. In particular the user may create a log file of transactions. When the MPS is run, the normal method is to begin logging all transactions. The user may then switch this off, if desired (see Figure 16). At present it only serves as a tool for forensic evaluations of activity. In the future it may be the basis for reconstructing the MPS if failure occurs. The user is encouraged to disable this feature when not debugging because long disk access times cause this feature to slow the MPS. 
Figure 16 - Turning MPS Log Files Off The MPS also keeps times of transactions. The default is on, and is useful for log file transactions. Since this is not time consuming, it is not worth the effort to disable, but if the user is inclined, the code in Figure 17 will do so. At present there is no user access to messages, in the future we may consider access to the messages, including time stamp information. 
Figure 17 - Turning Off Time Logging for Messages In some cases there may not be a 0 level client (as in a pre and post-processing model). If this is the case, there may not be another client to change the destination group of the message, and as a result will cycle through the group indefinitely. To counter this, a flag may be set which will discard messages passing priority level 0, when there is no client present at level 0. The example in Figure 18 shows how to disable this feature (the default is on). 
Figure 18 - Turning Off The Zero Level Priority Message Blocking Feature 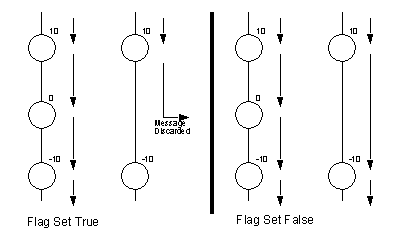
Figure 19 - The Effect of Turning off the Zero Level Priority Message Blocking Feature There are a number of functions of MPS which are under development, or in planning. These are listed below with some descriptions. i) Blocking/Non-Blocking General Broadcasts to a group - this has been discussed at the end of Section 2.3 - Direct Instance Connection. ii) Recovery from log file in the event of an MPS failure (i.e., crash). iii) A method for detecting and removing connections to clients which have crashed (and thus are not present). It is possible that a client may not deinitialize properly. If this is the case, messages may wait indefinitely for the client. iv) Message time stamps - A message may be stamped with an expiry time, after which it is discarded if not read. The other case is a message which is to be held until a specific time, at which it will be made available for reading. v) The deinitialization function will allow the connection between the MPS and the instance to be closed, but the internal data structures of MPS are not adjusted. Until this is fixed, missing clients may block messages. vi) Getting lists of all groups on the message board. vii) Interfaces written in other languages, and on other operating systems. viii) Having concurrently running MPS servers. This would help overcome the bottleneck problem. ix) Give the user access to waiting, and written messages to examine content and time stamps. This feature might require some examination of security issues. 5.0 - Non-MPS Communication (Point - to - Point) For transmitting blocks of data (large objects) it is desirable to go around the MPS, and directly between clients. To do this a set of subroutines are available to the instance program. The example below shows two programs which use the MPS to trade specific information about socket numbers and host names, and then pass data directly (see Figure 20) 
Figure 20a - Direct Socket Connection Between Programs Using the MPS 
Figure 20b - Direct Socket Connection Between Programs Using the MPS 6.0 - MPS for CAPP/PPC Integration The description in the earlier sections are best illustrated with an application. A practical example which is being developed at UWO is the integration of CAPP (Computer Aided Process Planning) and PPC (Production Planning and Control). To do this we are using a program called RPE (Reactive Planning Environment) developed at McMaster University. CAPP will issue process plans for individual parts and products. These process plans contain a number of alternative operations. What RPE will do is allow the process planner to chose the optimum set of operations in the process plan. These choices are often dependant on available resources. The problem which arises between CAPP and PPC is that when a collection of process plans are produced with CAPP and RPE, all of the resources are assumed to be available. In reality PPC will have an ongoing revision of resource availability. Quite often PPC can resolve scheduling problems, but when it cannot, a replanning process must occur. Thus, the existing integration problem is a question of how to include the machine availability in process planning. The purpose of the integrator is to resolve the feedback problem by using RPE to try short term replanning. The integrator will have two functions. The first function is to store process plans, and resource data. The second function is to receive events (demands, requests, and reports) and as a result send data and requests/reports to other programs in the system. The reader should note that the software is cleanly divided into 4 sections: CAPP; PPC; RPE; The Integrator. To bring this software together in a networked environment we have used the MPS. Each of these programs has been given its own group. An MPS graph is shown below in Figure 21, and as can be seen, the structure is very simple at this point. 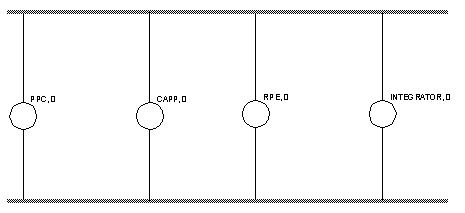
Figure 21 - The fundamental MPS Graph for CAPP/PPC Integration (Keeping in mind that the structure above is intended for event reporting only) The PPC group should only be an interface to an individual PPC package. While on the other hand, the CAPP group is suited to a large number of concurrent instances. The information used by RPE will be provided by the integrator, therefore the RPE group could also contain a large number of concurrent instances. Finally, the integrator must be run by itself, because it acts as a gateway for all transactions, and is not suited to concurrency. 7.0 Discussion and Conclusions This message passing system provides an excellent tool for developing distributed applications. Because of its structure it may be independant of language, platform, and user interface. The cost of all of the advantages discussed is a decrease in speed of communication. Thus, for applications with time constraints, a synchronous system is much more advisable. If a distributed system has a number of largely independant tasks, MPS will provide an excellent interface environment. This is largely the result of the original effort to use MPS for, - manufacturing workcell control - design and production function integration - distributed graphical applications such as ray tracing and design. The MPS approach also has an approach which focuses on event flow, instead of data flow. This makes the system more intuitive for the designer and more like a traditional user interface to the programmer. MPS also allows the ad-hoc addition of foreign processes for diagnosis and observation, which is difficult or impossible in the traditional point-to-point systems. As stated before, MPS does not attempt to replace existing distributed processing methods, but instead provide a method which can coexist with them, and allow distributed computing functions not previously available. Appendix A - Function Names/Definitions These functions have been labelled with a note which indicates which are optional, and in which order they may be used. 2 - before initialization with the MPS 3 - initialization with the MPS (required 1) int mb_clear_client(client_info *CLIENT_INFO, char *file_name) Clear Data Structure - This declaration will clear all of the fields in the CLIENT_INFO structure. ‘file_name’ is the name of an ASCII file contains a machine name, or IP number on the first line, and a socket number on the second line. This is for the MPS. This function does not initialize a client, but must be called before any other functions are called. Returns ERROR or NO_ERROR. (optional 2, 4) int mb_set_timeout_interval(client_info *CLIENT_INFO, int duration) Set Timeout - If any read or write to the MPS has failed, this function will determine the number of seconds to wait before quitting. The default is 30 seconds. This only has an effect if the socket connection to the MPS has failed. Returns ERROR or NO_ERROR. (optional 2) int mb_set_priority(client_info *CLIENT_INFO, int priority) Set Priority - Must be called before ‘mb_init_client()’ to set the priority of the client. If not called, the default is 0. Returns ERROR or NO_ERROR. (optional 2) int mb_set_sequence(client_info *CLIENT_INFO, int sequence) Set Sequence - This will declare that a concurrent set of instances is sequential (sequence = SEQUENT) or non-sequential (sequence = NON_SEQ). The default is non-sequential, but if this is called, it over-rides all settings for the other concurrent instances (at the same group and priority level). Returns ERROR or NO_ERROR. (required 3) int mb_init_client(client_info *CLIENT_INFO, char *name) Initialize Client - This function establishes a connection to the MPS. The group is determined by the string in ‘name’. Returns ERROR or NO_ERROR. (option 4) int mb_get_client_group(client_info *CLIENT_INFO, char *name) Get Group Number - Each group has an index (or key reference number). To find the number of another group this function is called with the name of the remote group ‘name’. If the group is found the integer value is returned, or else ERROR is returned. (option 4) int mb_set_flag(client_info *CLIENT_INFO, int type, int state) Set A Flag - This allows a remote flag to be set on the MPS. This returns ERROR or NO_ERROR. The flag types are setting are explained below. - MESSAGE_LOG_FILE - If set TRUE (the default is TRUE) the MPS will save a copy of every message received, every message read, and every message deleted. This feature will slow the MPS because of disk access times, the user is encouraged to turn this off. - MESSAGE_TIME_STAMP - Will turn on a function that logs the time when messages arrive, are read, and are deleted. The default is TRUE. - ZERO_PRIORITY_BLOCKING - The default is TRUE. If set all messages will be discarded if there is no 0 level priority instance when they pass 0 level priority. (option 4) int mb_encapsulate(client_info *CLIENT_INFO, int priority, char *group, char *encapsulated_group) Encapsulate a Group - This function will cause the named ‘encapsulated_group’ to be encapsulated as an instance in ‘group’ at ‘priority’. The reader should note that this encapsulated group is created automatically as if it is a different instance than represented by ‘CLIENT_INFO’, so the calling routine does not have to perform any setup. Returns ERROR or NO_ERROR. (option 4) int mb_send_message(client_info *CLIENT_INFO, int from_group, int to_group, int cmd, char *string) Send Message to Group - This function will post a message on the MPS which will appear to come from ‘from_group’, and will travel to ‘to_group’. The message content is ‘cmd’ and ‘string’. Returns ERROR or NO_ERROR. (option 4) int mb_get_message(client_info *CLIENT_INFO, int *from_group, int *to_group, int *cmd, char *string) Get Message - This function will get any message waiting on the MPS. If any messages are waiting, the messages directly from other instances will be retrieved first. If the message is from an instance, the ‘from_group’ value will contain the instance number, if the message comes from a group the ‘from_group’ number will be a group number. ‘to_group’ is the destination group or instance of the message (if the message was to an instance, this will be an instance number, otherwise it will be a group number). The ‘cmd’ and ‘string’ values have been set by a remote instance. If no message was available, ERROR is returned, otherwise NO_ERROR is returned. The length of string will never be longer than MAX_STRING_LENGTH. (required 5) int mb_deinit(client_info *CLIENT_INFO) Deinitialize Client Instance - This breaks the socket connection to the MPS, but does not yet deinitialize the data structures on the MPS. Returns ERROR or NO_ERROR. (optional 4) int mb_unset_filter(client_info *CLIENT_INFO, int group) Remove Group From Filter List - If a group is on the filter list, and the client wants to remove it, this function may be called. Refer to mb_set_filter() for details of filters. Returns ERROR or NO_ERROR. (Not implemented yet) (optional 4) int mb_set_filter(client_info *CLIENT_INFO, int group) Set Input Filter - If called it will set a filter on messages which may be received. The mechanism is list based. If the list is empty, messages from all groups may be accepted. To clear the list, set ‘group = ALL_GROUPS’ When ‘group’ is a real group number, that group will be appended to the list. If the list has any groups on it, messages from those groups will be the only ones accepted, until the list is cleared. Returns ERROR or NO_ERROR. (optional 4) int mb_instance_number(client_info *CLIENT_INFO) Find Local Instance Number - Will return the instance number, or ERROR. The user should recall that each instance is given a distinct reference integer number, which other instances ore not given access to. Returns ERROR if instance number not available. (optional 4) int mb_send_message_ins(client_info *CLIENT_INFO, int to_instance, int cmd, char *string) Send a Message to Instance - Will send a message to instance number ‘to_instance’. The user is reminded that the destination must first be found from the remote instance. These functions are more sophisticated than the previous routines. The routines require a synchronous connection between processes. What this means is that one process must be waiting for a connection. Another process must be waiting for a connection. Another process must connect, and then all communication must occur in an agreed sequence. The function descriptions below are preceded with an indication of which process will use them. In this terminology the server will be the process which has initiated a connection. Order numbers are also provided in this section. (Server 1) int mb_con_wait(client_info *CONNECT, int local_socket) Wait for Connection - This function will be called, and will not return until a remote client has connected. If the remote client has connected successfully NO_ERROR will be returned, else ERROR will be returned. The ‘local_socket’ number is arbitrarily chosen by the user/instance. The user is responsible for informing the remote client about the socket number, and host machine name being used. (client 2) int mb_con_make(client_info *CONNECT, char *remote_server_name, int remote_server_socket, int local_client_socket) Make Connection With Waiting Client - Once a server is waiting for a connection, this function may be called to make the connection. The user must know the ‘remote_server_name’ and the ‘remote_server_socket’. The ‘local_client_socket’ is arbitrarily chosen by the user. This function returns NO_ERROR if the connection was successfully made, else ERROR is returned. (client/server 3) int mb_con_send(client_info *CONNECT, char *string) Send Data Through Direct Connection - Will send ‘string’ to the remote client/server. The remote party must be waiting. If the ‘string’ was not sent ERROR will be returned. (client/server 3) int mb_con_receive(client_info *CLIENT_INFO, char *string) Get Data From Direct Connection - Is used when a string is expected to be received. This function must be called before a ‘string’ is sent. If a string was received this function will return NO_ERROR. (client/server 3) int mb_con_loop(client_info *CONNECT, char *string) Send and Receive Data From Direct Connection - This uses the send and receive functions above to send a message to a remote connection and then wait for a reply. If the value of ‘string’ was sent, and a new ‘string’ has replaced it, NO_ERROR will be returned. (server/client 4) int mb_con_close(client_info *CONNECT) Close Direct Connection - This will break the connection made and used by the previous functions. This function should be called by both the client and server to close their connections. The function returns ERROR, or NO_ERROR. Appendix B - Software Structure The structure of the software may be illustrated with a simple diagram showing the major software modules, and where they fit in. 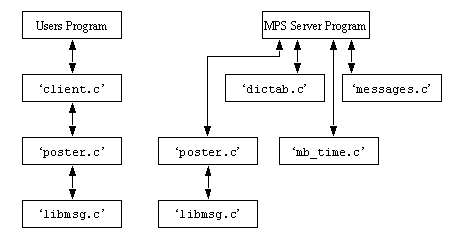
Figure b.1 - A picture of the software structure of the MPS (note that some software routines are shared) All of these modules use the ‘define.c’ functions for common definitions of messages. A quick description of each module is given below. define.c - Some basic information and functions for message handling. libmsg.c - The low level socket drivers, with no protocol. poster.c - The protocol for message passing using the routines in ‘libmsg.c’. client.c - Converts the users function calls into message board requests, and interprets the responses. dictab.c - Stores and allows manipulation of information about instances using the MPS. messages.c - Stores messages and recalls them upon request. board.c - Handles all executive functions for coordinating clients, messages, and requests. mb_time.c - Creates time strings from system. Appendix C - Linking and Running MPS The example UNIX ‘makefile’ shows how to link the MPS utilities to an application (see Figure C.1 below). 
Figure c.1 - A Sample UNIX makefile for a test program which uses the message board The MPS program is called ‘board’, and must be run on a particular machine before the application programs. The application programs and MPS must be directed to the same file containing the host IP number, and socket number, which MPS will run from. If the file already exists, and MPS finds a problem with it, it will attempt to correct the problem. If no file is found MPS will fail to start correctly, and communications will fail. This file may be specified to MPS when it is run, 
The user then runs their program which also refers to the same file. Client - Used interchangeably with instance. Group A group is a collection of instances which perform parts of a function. The order in which each instance operates is determined by their priority. The suggested mode of addressing messages is to a group. Instance A program which has a connection to the MPS. If a program has more than one connection to the MPS will to represent more than one instance. Each instance is described with a group name and priority number. Message An integer and string combination passed between instances. The contents of the integer value and the string are left to the instances. Message Board Used interchangeably with MPS. MPS Message Passing Secretary - A central server which communicates with each instance, and handles all message passing between instances. The communications between instances is determined by an ad-hoc graph structure set up when the instances and initialized and deinitialized. Priority A numerical order in which instances will receive a message. If the two or more instances have the same priority in the same group, they become concurrent. Agha, G. and Hewitt, C., 1987, “Concurrent Programming Using Actors”, in the book “Object Oriented Concurrent Programming”, edited by A. Yonezawa and M. Tokoro, The MIT Press, pp. 37-53. Andrews, G. R., 1991, “Concurrent Programming Principles and Practice”, The Benjamin/Cummings Publishing Company. Birman, K. P., 1991, “The Process Group Approach to Reliable Distributed Computing”, July 1991, Department of Computer Science, Cornell University. Buhr, P.A. and MacDonald, H. I., 1991, “uSystem Annotated Reference Manual”, Department of Computer Science, The University of Waterloo, Waterloo, Ontario, Canada. Grimshaw, A. S., 1991, “An Introduction to Parallel Object-Oriented Programming with Mentat”, Computer Sciences Report No. TR-91-07, April 4, 1991, University of Virginia. Jack, H. and Buchal, R. O., 1992, “An Automated Workcell for Teaching and Research”, to be published in The Western Journal of Graduate Research, The University of Western Ontario. Otto, A., 1991, “MetaMP: A Higher Level Abstraction for Message-Passing Programming”, Department of Computer Sciences and Engineering, Oregon Graduate Institute of Sciences and Technology. Sikorski, J., 1991, “Sifting Through Silicon; Features of Parallel Computing Architectures”, Sunworld, April 1991, pp. 39-45. Singh, A., Schaeffer, J. and Green, M., 1991, “A Template-Based Approach to the Generation of Distributed Applications Using a Network of Workstations”, IEEE Transactions on Parallel and Distributed Systems, Vol. 2, No. 1, Jan., 1991, pp. 52-67. Strom, R. E. and Yemini, S., 1983, “NIL: An integrated language and system for distributed programming”, SIGPLAN Notices 18, 6 (June), pp. 73-82. 1.1 MATHEMATICAL ELEMENTS OF COMPUTER GRAPHICS1.2 LINE DRAWING1.3 POLYGON DRAWING1.4 SHADED POLYGONS1.5 COLORS1.6 DITHERING1.7 RAY TRACING1.8 RADIOSITY1.9 ADVANCED GRAPHICS TECHNIQUES1.10 REFERENCES1.11 PRACTICE PROBLEMS1.13 VIRTUAL REALITY1.14 MULTIMEDIA1.3 VISIONS SYSTEMS1.4 PRACTICE PROBLEMS1.12 SIMULATION1.6 PLANNING1.7 NEURAL NETWORK THEORY1.8 ARTIFICIAL INTELLIGENCE (AI) |