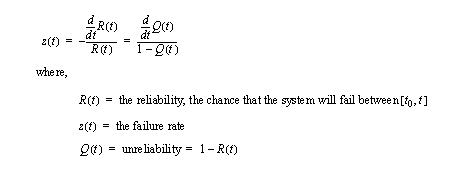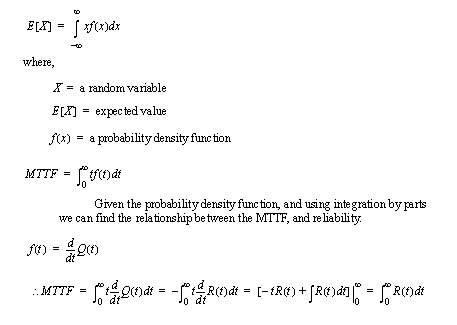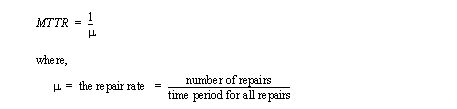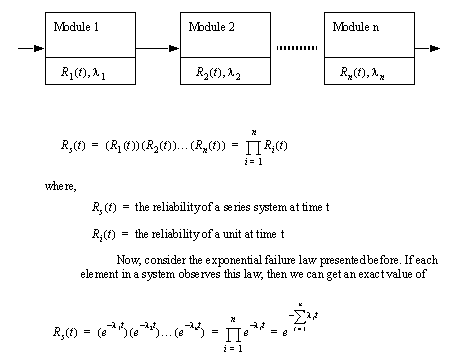10.1 SYSTEM FAILURE
10.1.1 Introduction
• Basic concept, anticipate things going wrong, and determine what to do ahead of time.
• Key terms,
backup - a secondary system that can be used to replace the primary system if it fails.
fail operational - even when components fail, the system continues to operate within specifications.
fail safe - when the system fails, it does not cause damage, and possibly allows continued operation outside of specification.
failure tolerant - in the event that one system component fails, the entire system does not fail.
prime - a main system that is responsible for a task.
redundant - secondary systems that run in parallel with the prime, and will be able to hot swap if the prime fails.
time critical - the system has a certain response time before a failure will occur.
• essential components in these systems are,
monitoring systems - check for sanity or failure of systems. The purpose of these system is detection and reporting of failures.
emergency control functions - these functions will switch control when faults are detected. In some cases this might include human intervention, and be triggered automatically. These systems are intended to eliminate or reduce the effects of a failure.
• safety criticality might be categorized as below,
Criticality I - Catastrophic
- causes human disability/death
- causes loss of equipment
Criticality II - Critical
- causes major human injury
- lose use of emergency system
- major damage to essential equipment
Criticality III - Marginal
- minor human injury
- major damage to emergency system
- minor damage to essential equipment
• safing is a process whereby a system that has failed is shut down appropriately (i.e., actuators shut down, brakes applied, or whatever is appropriate to the situation).
• safing paths often include,
- braking equipment
- removal of power to actuators
- consideration of complete power failure
- operator control should be available, even when automated systems are in place
- multiple safing paths should be available
• the operator will be a good decision maker. Possible options include,
- safing procedures
- attempt to manually repair
- ignore
• techniques used are,
- checksums
- parity bits
- software interlocks
- watch dog timers
- sample calculations
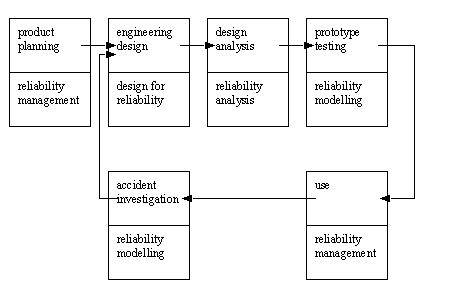
• The role of various reliability programs can be related to a product life cycle.
10.1.2 The Theory of Module Reliability and Dependability
• Dependability is a combination of,
- reliability - the probability that a system operates through a given operation specification.
- availability - the probability that the system will be available at any instant required.
• Failure rate is the expected number of failures per unit time, and is shown with the constant (lambda), with the units of failures per hour.
• Basically,
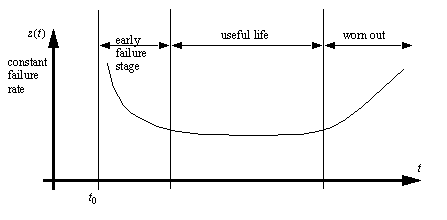
• The bathtub curve shows typical values for the failure rate.
• The basic reliability equation can be rearranged, eventually leading to a compact expression,
• MTTF (Mean Time To Failure) - this is the expected time before a failure.
• The MTTR (Mean Time To Repair) for a system is the average time to repair a system. This is not simple to determine and often is based on experimental estimates.
• The MTTF and MTTR both measure the time that the system is running between repairs, and the time the system is down for repairs. But, they must be combined for the more useful measure MTBF (Mean Time Before Failure),
• The difference between MTBF and MTTR is often small, but when critical the difference must be observed.
10.1.3 The Theory of System Reliability
• Fault Coverage is the probability that a system will recover from a failure. This can be derived approximately by examining the design, and making reliable estimates. This number will be difficult to determine exactly because it is based on real, and often unpredictable phenomenon.
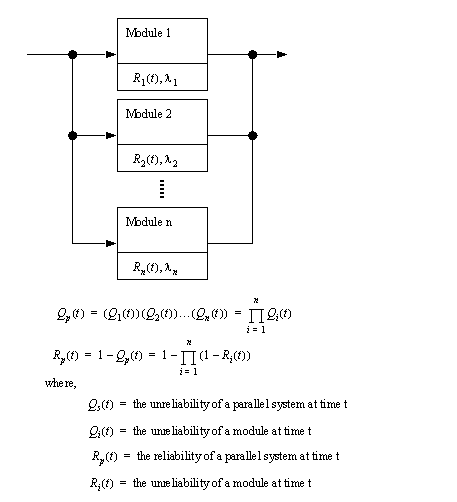
• Reliability can be determined with individual system components as a function of probabilities. The two main categories of systems are series, and parallel (redundant). In the best case a high reliability system would have many parallel systems in series.
• In terms of design, a system designer must have an intuitive understanding of the concept of series/parallel functions.
• We can consider a series system where if any of the units fails, then the system becomes inoperative. Here the reliabilities of each of the system components is chained (ANDed) together.
• We can also consider a parallel system. If any of the units fails the system will continue to operate. Failure will only come when all of the modules fail. Here we are concerned with complements of the chained unreliabilities.
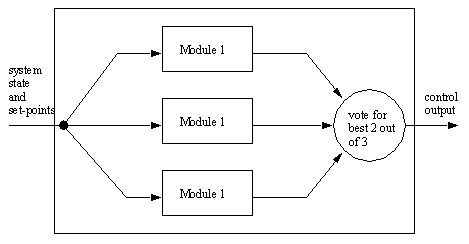
• also consider the case of a parallel system that requires ‘m’ of ‘n’ identical modules to be functional, such as a hybrid system, or a voting system that needs two out of three functional units. The student will consider the binomial form of the probabilities.
• keep in mind that many systems are a combination of series and parallel units, to find the total reliability, calculate the reliability of the parallel units first, and then calculate the series reliability, replacing the parallel units with their grouped reliability.
• availability is the chance that at any time a system will be operational. This can be determined experimentally, or estimated. For a system that is into it’s useful lifetime, this can be a good measure. Note that at the beginning, and end of its life, this value will be changing, and will not be reliable.
10.1.4 Design For Reliability (DFR)
10.1.4.1 - Passive Redundant
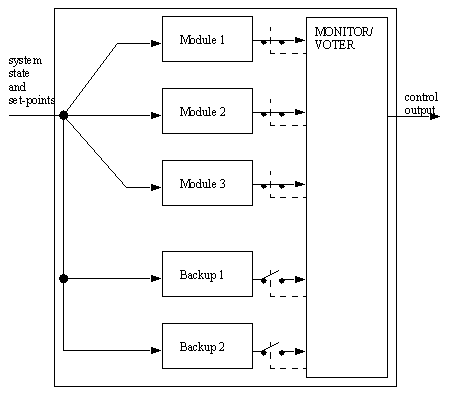
• three identical, yet independent systems are used to produce three outputs. The three outputs are compared and a voting procedure is used to select one. This method is called Triple Modular Redundancy (TMR)
• In this event, if there is a random failure in any of the modules, it will be outvoted by the others, and the system will continue to operate as normal.
• This type of module does not protect against design failures, where all three modules are making the same error. For example if all three had Intel Pentium chips with the same math mistake, they would all be in error, and the wrong control output would result.
• This module design is best used when it is expected that one of the modules will fail randomly with an unrecoverable state.
• This type of system can be used easily with computer algorithms and digital electronics.
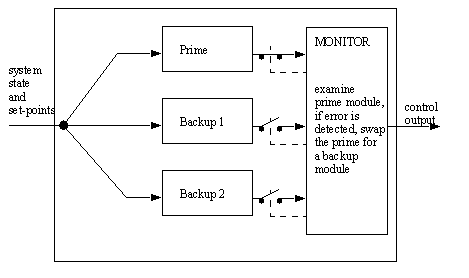
10.1.4.2 - Active Redundant
• A separate monitoring system tracks the progress of separate modules. In the event one of the modules is believed to have failed, it is taken off line, and replaced with a new module.
• This method depends upon a good design of the monitor module.
• As with the passive redundant module, this module is also best used to compensate for complete module failure.
• This type of system can be used easily with analog electronics and mechanics, as well as with switched modules.
10.1.4.3 - Hybrid Active
• A combination of the voting system and the reconfiguration system
• the voting modules continue to make decisions, but voting members can be replaced with backup units.
10.1.4.4 - Other Design Points
• Parity and check bits can be used to detects errors in calculations. Checksums can be used for blocks of data, and grey code can be used for detecting errors in sequential numbers.
• The amount of redundant hardware can be reduced by doing the same calculation twice, at different points in time on the same processor. If the results are compared, and found to be different. This would indicate a transient fault. This can be important in irradiated environments where bits can be flipped randomly.
• Software redundancy involves writing multiple versions of the same algorithm/program. All of the algorithm versions are executed simultaneously. If a separate acceptance algorithm estimates that the primary version is in err, it is disabled, and the secondary version is enabled. This continues as long as remaining modules are left.
10.1.5 Formal Methods For Failure Modelling
• There are a number of steps required to properly evaluate a system for fault probabilities.
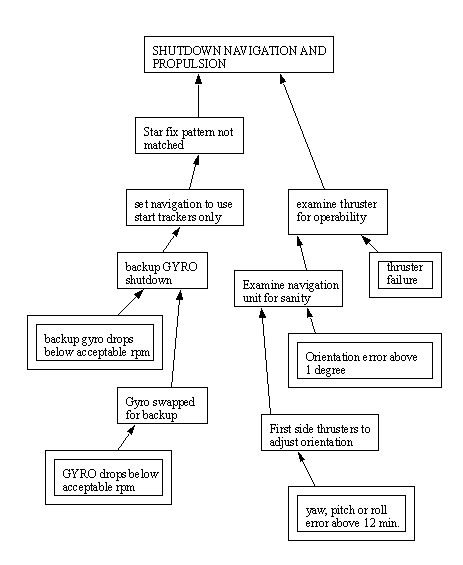
10.1.5.1 - Event Trees
• These trees match outside events in the system to actions of the system. When applied to safety systems we can related failures to actions of the safety systems.
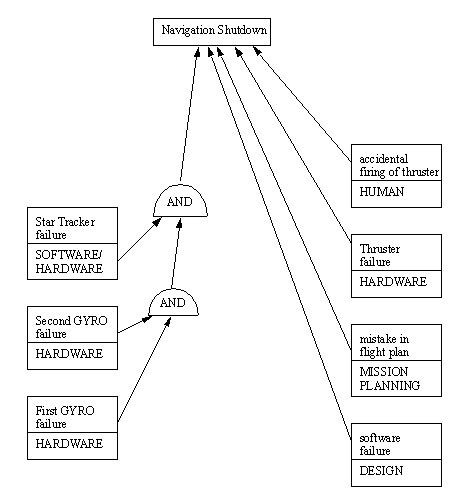
10.1.5.2 - Fault Trees
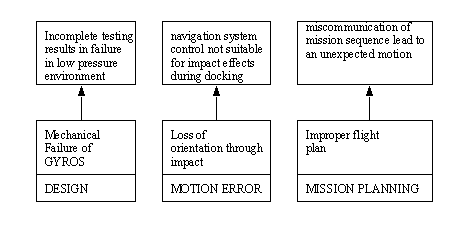
• Fault trees try to relate events in the system to causes of failure that will cascade to the point of a safing, or failure.
• A simple example is given below
10.1.5.3 - Causes Trees
• Causes trees can be used to focus on controlling error situations.
• Note Ishikawa/fishbone diagrams used in quality control are useful here, as well as Pareto diagrams for selecting problems for elimination.
10.1.6 Error Sources
• Humans are very flexible, and are capable of adapting to many diverse situations. On the other hand this creates the ability to make mistakes.
• An estimate of human error rates, for trained operators was made available for nuclear power plant operation [Rasmussen et. al., 1987, pg. 136],
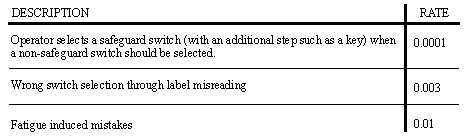
• Another table of human error estimates is given below. [Leveson, 1995, pg.353]
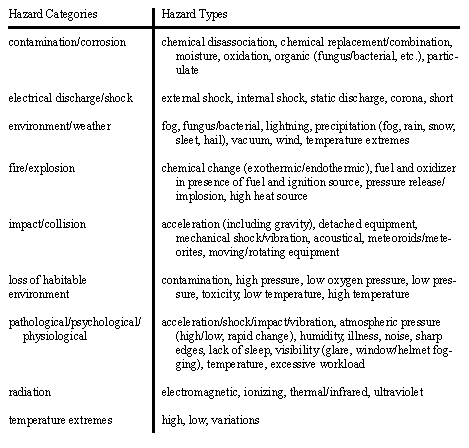
• A list of generic hazards for the space shuttle was found in [Leveson, 1995, pg. 297],
10.1.7 Risk Control During Design
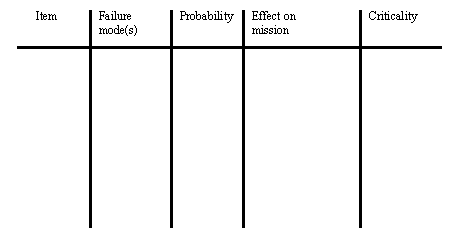
10.1.7.1 - Failure Modes and Effects Analysis (FMEA)
• Estimates overall reliability of a detailed or existing product design in terms of probability of failure
• basically, each component is examined for failure modes, and the effects of each failure is considered. In turn, the effects of these failures on other parts of the system is considered.
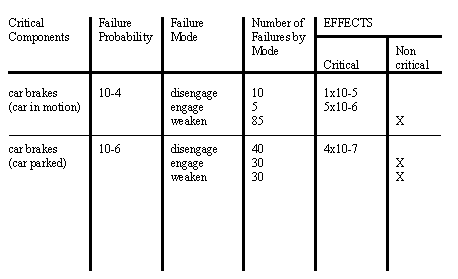
• the following is a reasonable FMEA chart.
• the basic steps to filling one out is,
1. consider all critical components in a system. These are listed in the critical items column.
2. If a component has more than one operation mode, each of these should be considered individually.
3. estimate failure probability based on sources such as those listed below. Error bounds may also be included in the FMEA figures when numbers are unsure. These figures are entered in the “Failure Probability” column.
- historical data for similar components in similar conditions
- published values
- experienced estimates
- testing
- etc.
4. The failures in a particular operation mode can take a number of forms. Therefore, each mode of failure for a system is considered and its % of total failures is broken down.
5. In this case the table shows failures divided into critical/non-critical (others are possible). The effects are considered, and in the event of critical failures the probabilities are listed and combined to get the overall system reliability.
• Suitable applications include,
- analyze single units or failures to target reliability problems.
- identify,
- redundant and fail-safe design requirements
- single item failure modes
- inspection and maintenance requirements
- components for redesign
• This technique is very complete, but also time consuming.
• not suited to complex systems where cascaded errors may occur.
10.1.7.2 - Critical Items List (CIL)
• This list can be generated from an FMEA study
• This might look like the table below,
10.1.7.3 - Failure Modes, Effects, and Criticality Analysis (FMECA)
• This is basically FMEA with greater analysis of criticality
• this involves additional steps including,
- determining the means of control
- the results of the FMEA are reconsidered with the control factors
10.1.7.4 - Hazard Causal Analysis (HCA)
• A process where hazards are considered for their causes and their effects. The results of this analysis is used for control of hazards.
• The causes and effects can be extensive, and must be determined by a person/team with a good knowledge of a system.
• the analysis may focus on whole systems, or subsystems.
• it can be helpful to trace causes and effects both forwards and backwards in a system.
• Sensitivity analysis can be used to determine the more significant causes/effects.
• Some categories of this analysis are,
System Hazard Analysis - the entire system is considered at once, including interactions of components, interfaces to operators, modes of operations, etc. This is meant for global system failures creating hazards.
SubSystem Hazard Analysis - individual subsystems are examined individually. The effect of a failure of one subsystem on the entire system is considered. This evaluates individual system failures creating hazards.
Operational Hazard Analysis - an analysis of the detailed procedures of operation, and how a deviation from these procedures could lead to a hazard. Variations in the procedure could be unexpected events, operator errors, etc.
10.1.7.5 - Interface Analysis
• relationships between modules can be categorized as,
- physical
- functional
- or flow
• typical problems that arise are,
- a unit or connection fails, resulting in a loss of data across the interface
- a partial failure of a unit or connection results in a reduced flow across the interface
- there is an intermittent or unstable flow across the interface
- there is an excessive flow across the interface
- unexpected flow could result in unexpected operation, or functional failure
- undesired effect - the interface is operating as specified, but additional undesired effects are present. For example heat flow across a conductor.
• This analysis is best done by a team of experts familiar with the modules being interfaced.
10.1.8 Management of Reliability
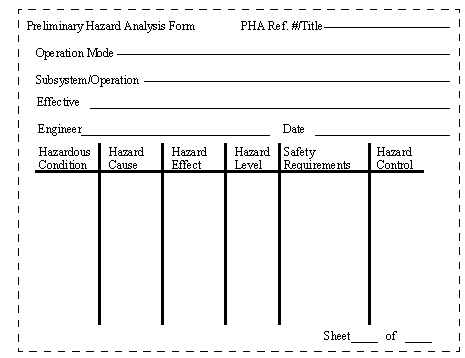
10.1.8.1 - Preliminary Hazard Analysis (PHA)
• As the name suggests this procedure is carried out early in projects.
• typically this involves,
- determining hazards that might exist and possible effects
- determine a clear set of guidelines and objectives to be used during a design
- create plans to deal with critical hazards
- assigning responsibility for hazard control (management and technical)
- allocate time and resources to deal with hazards
• The results of this analysis are used for preparing specification, testing, implementation, maintenance and management.
• The modules within the system must be clearly identified, with consistent boundaries.
• Specific hazards may be obvious, or they may be mandated by government regulations.
• Some hazards can be identified by,
- examining similar existing systems
- review existing checklists and standards
- consider energy flow through the system
- consider inherently hazardous materials
- consider interactions between system components (e.g., materials corrode or power drain)
- review previous hazard analysis for similar systems
- review operation specifications, and consider all environmental factors
- use brainstorming in teams
- consider human/machine interface
- consider usage mode changes
- try small scale testing, and theoretical analysis
- think through a worst case what-if analysis
• Hazard forms are not completed all at once, but as project steps develop.
• Hazard level (either likelihood and/or effects) should be indicated on a PHA, these levels are specific to the application. For example, NASA uses 1, 1R, 2, 2R, etc. Other methods may have several divisions between ‘impossible’ to ‘always’.
• Design criteria are used to specify constraints on a design to minimize or prevent a hazard. For example the hazard of an engine still running even after controller power has failed suggests that the motor must not operate when controller power is off.
• The operational phase which a hazard might occur in must also be considered. Some hazards will become more/less severe over the operational life.
10.1.9 Implemented Risk Management Programs
10.1.9.1 - NASA Safety Methods
• A large part of NASA’s policies deal with identifying potential problems, and eliminating or reducing them. This system has been recognized as successful and sufficient when properly implemented [Leveson, 1995, pg. 274]. These are not described in detail here, as they are somewhat distant from the design process, although they do provide a valuable source of feedback and control.
• NASA bases most of it’s analysis of systems on FMEA and CILs. (The CIL below is from [Leveson, 1995, pg. 283])
• The FMEA is done by contractors and, based on the results a criticality is assigned to each item.
1 - failure could cause loss of life or vehicle
1R - failure could cause loss of life or vehicle, but redundant hardware is present
1S - a ground support element that could cause loss of life or equipment
2 - failure could cause loss of mission
2R - failure could cause loss of mission, but redundant hardware is present
2S - a ground support system that could cause loss of vehicle systems
3 - other failure types that may cause less severe damage without catastrophic effects on the mission
• Items rated 1, 1R, 2, 2R must be on the CIL.
• Items on the CIL must be redesigned or improved to fail safe, or else they will require that a special waiver be granted.
• EIFA (Element Interface Functional Analysis) is used to evaluate the effects of failure modes in either component on other components.
• These procedures don’t typically extend to software, although efforts were made to consider its effects. And, future efforts are expected to address some aspects.
• Other types of hazards are considered by,
- PHA (Process Hazard Analysis)
- SHA (Subsystem Hazard Analysis)
- OHA (Operations Hazard Analysis)
10.1.10 References and Bibliography
American Institute of Chemical Engineers, Guidelines for hazard evaluation procedures: with worked examples, 2nd edition, 1992.
Brimley, W., “Spacecraft Systems; Safety/Failure Tolerance Failure Management”, part of a set of course note for a course offered previously at the University of Toronto, 199?.
Dhillon, B.S., Engineering Design; a modern approach, Irwin, 1996.
Dorf, R.C. (editor), The Electrical Engineering Handbook, IEEE Press/CRC Press, USA, 1993, pp. 2020-2031.
Leveson, N., Safeware: system safety and computers, Addison-Wesley Publishing Company Inc., 1995.
Rasmussen, J., Duncan, K., and Leplat, J., New Technology and Human Error, John Wiley & Sons Ltd., 1987.
Ullman, D.G., The Mechanical Design Process, McGraw-Hill, 1997.