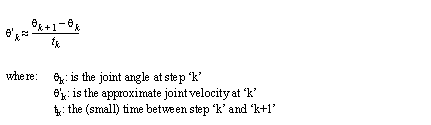changes in sensor characteristics.
The remainder of this chapter is concerned with the application, and evaluation of neural networks in Motion Planning. In particular, the chapter will discuss the application of neural networks to discrete time step path planning, the training of the neural network, and the testing for training convergence.
7.2 6.2 Discrete Time Step Planners, and Neural Networks:
When a control system operates with discrete time steps, there are two time step related phenomena which dictate the performance. The first is based on the natural, or resonant frequencies of the system. If the controller is operating (refreshing) at a frequency below that of the system, then the system will become unstable. This “aliasing” problem is eliminated by making the controller run faster than the Nyquist Frequency (at least twice the system frequency). The natural, or resonant frequency of the robot may be determined easily under the influence of gravity. When no gravity is present, the system will have a “natural coupling frequency” between the joints, which is a variable of the robot configuration. This constantly changing frequency is very difficult to find, and thus will be neglected.
The second phenomenon is based on the time step of the controller. Many controllers examine a time series of inputs, to determine the next control action. The inputs in the time series are assumed to have a time step of known value. If, for some unknown reason, this time step varies, then the controller may respond differently. For example, doubling the controller clock speed might result in the controller doubling the control output value. The controller can be made to be time dependant, or independent.
If the controller is time dependant, then it will require a fixed time interval for calculation. This means that the controller must be designed around a specific clock rate, or must have an internal clock. If this is not desired, the preferred system is the one in which the operation is time independent. If the complete system state is described to the controller, then it may make an instantaneous decision that is time independent. Effectively this means that the time dependant ‘calculations’ are done outside the controller. One example is velocity, which may be supplied to the controller, instead of being calculated in the controller.
The advantages of time independent control are,
The planner time step may be variable, so expensive timing clocks are not needed, and control programs do not need precise timing.
The Neural Network architecture will be simpler,
The control model may be the equations of motion,
The disadvantage of time independent control is,
Extra hardware is required outside the controller to differential and integrate feedback signals.
Thus, the time independent controller should provide stability over a variety of time steps that do not approach the Nyquist Frequency for the controlled system. (Neuman and Tourassis [1985] suggested that 10 ms is a standard time step for manipulators.)
7.3 6.3 Time Optimal Discrete Time-Step Paths:
A motion plan may be described with a set of system states and the control outputs that exist between time steps. In the ideal continuous case, the duration of a time step is assumed to decrease until near zero, thus the number of time steps becomes infinite and continuous. Since the neural network controller will have discrete (not continuous) time steps, motion plans will be described with a finite number of steps. Since the actual controller will not run at near infinite speeds, the ‘coarse’ nature of the system must be considered.
The discrete nature of the path planner requires that the trajectories be produced with steps in the output values, rather than continuous functions. Some of the conditions that will be imposed upon the discrete time step motion are: i) that there be at least one control step, ii) that motion be complete in the least number of time steps possible (for optimal time), and iii) that motion times be reduced by using maximum value control outputs when possible.
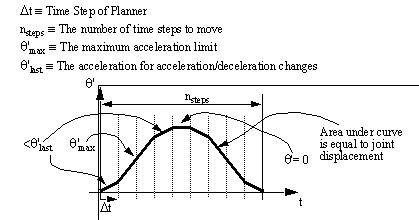
For simple velocity and acceleration control, motion may be represented with velocity profiles. When drawing the velocity profiles i) the motion may have an even or odd number of steps, ii) the joints may move to finish simultaneously, or in their own best time, iii) the paths will have start and stop positions, iv) the path will start and stop at rest, v) the slopes of the graph will represent the maximum/minimum acceleration, vi) the peak values will represent the maximum/minimum velocity, and vii) the area under the velocity profile will represent the angular displacement.
Figure 7.1 Figure 6.1: An example of a Velocity Profile (for Maximum Acceleration Planner)
7.4 6.4 A Neural Network Architecture for a Motion Planner
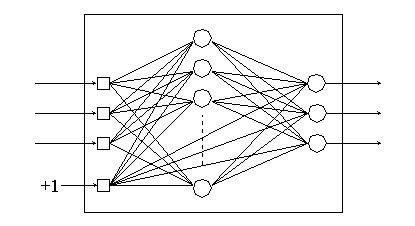
The neural network will consist of two layers, which have bias values applied to every neuron. This architecture is shown in the figure below
Figure 7.2 Figure 6.2: Neural Network Motion Planner Architecture
This network uses an appropriate number of input neurons (2, 4, and 6 for the three test cases), and output neurons, with 20 neurons in the hidden layer. Researchers have tried from 1 to thousands of neurons in this layer for various robotics problems. Examples of neuron counts may be seen in [Josin, 1988b][Josin et. al., 1988], where approximately 30 neurons are used. The activation function chosen for this application was the sigmoidal logistic function, which will represent the continuous nature of the mapping of inputs to outputs.
A bias neuron was connected to all neurons except for the input units. The bias neuron was chosen as an additional input, because previous research attempts without it have resulted in a much lower accuracy [Lee et. al., 1990][Jack et. al., unpublished].
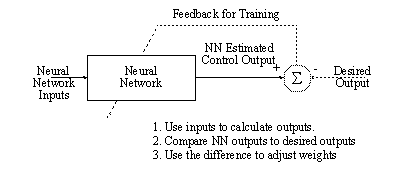
The Neural Network was trained with the backpropagation learning algorithm in a manner that is depicted below for illustration.
.
Figure 7.3 Figure 6.3: Basic Configuration for Neural Network Training
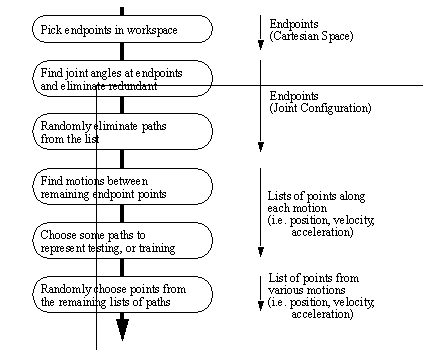
The optimal paths, which the neural network will be trained with, are found from algorithms before training. The basic procedure is as follows,
1. A set of points in space is chosen (described in section 6.6)
2. Optimal motion plans are found between all these points in space. (The motion plans consist of a sequential list of system states, accompanied by the near optimal control output. The number of steps in the path varies depending upon the path length, and the time step chosen.)
3. One training iteration involves presenting each input/output vector in the set (trajectories along path), to the neural network, as shown above, and then updating the training weights with the back propagation algorithm.
4. This is repeated until some measure of satisfaction is achieved.
Selection of training set data is described in the next section.
7.5 6.5 Neural Network Test and Training Data:
The properties of the data set must be established before the training and testing methods may be devised. In the realm of neural networks, the training and testing methods are determined by the quantity of data available.
Marko and Feldkamp [1990] suggest that a plentiful supply of data points warrants the use of a testing procedure that will train on one set of data points and be tested on another non-intersecting set of data points. This method is possible because any two arbitrary points within the robot workspace may be chosen as endpoints for a path. This means that the supply of data points is virtually infinite. Marko and Feldkamp also suggest that if training data points are scarce, initial screening for classification ability can be done with part of the set, then tested with another part of the set. This is valid only before the network is trained with all the set. The sparse training set procedures are,

As can be seen, the training and testing procedures, when using sparse data sets, are more involved, and require a better organization of training data. Using a reduced data set is not necessary and would actually lead to a more complex analysis, thus it will not be used. The method of choice will be to train with one data set, and test with another.
7.6 6.6 Training/Testing Data Set Generation:
Selection of sample data, for training neural networks, can determine the extent of success in estimating the optimal motions. Data sampling raises a few concerns: the data source; the collection method; the data properties; and the problem features represented in the data.
The data source could be a robot that is making an optimal motion. If this were the case then data collection errors would have to be considered like,
sensor noise,
transient vibrations,
variations between simulation models and the robot,
resolution in data collection,
mechanical friction and flexibility,
mechanical restriction would not allow some data to be generated,
noise from actuators, and joint controllers,
quantities like joint torques might be hard to measure.
Many of these sources of error would also manifest themselves when trying to implement the controller.
Marko and Feldkamp [1990] discuss some of the issues surrounding the collection of data for training the neural networks. They identify noisy data as one cause for poor network convergence, and longer training times. They also suggest that training data should be clustered around the operating points of the system, and also represent points from throughout the problem space. If the data set represents all the features of the problem, then the neural network will be able to generalize better.
The facilities available have encouraged the simulation of optimal motions, this eases the problem setup, and reduces data collection errors.
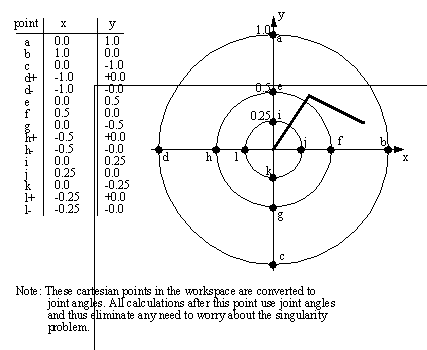
Descriptive data to represent the motion planning problem was characterized by a choice of points in space that were evenly distributed in polar robot work space coordinates. The arrangement for these points is shown below. Each of the 15 points shown serves as a start and stop point for a total of 210 paths. This is to say that there are paths from any one point to all other points.
Each of the 210 paths could then be interpreted 4 ways (resulting in 840 paths). These would involve start and stop joint configurations for the robot arm.
elbow up to elbow up,
elbow up to elbow down,
elbow down to elbow up,
elbow down to elbow down.
Note that if the arm starts with the elbow (joint 2) at zero degrees, one of two paths become redundant. If the elbow stops at zero degrees, then one of the other two paths will become redundant. For these cases the redundant paths were eliminated, and a total of 580 paths remained.
Every fifth path of the remaining list of 580 endpoints was then used to construct one data set that contained 116 paths. A second set was created in the same manner, with different values, from the original set of 580 paths. The optimal paths between the endpoints were then generated for all three (thesis) planner cases. Thus, there were six sets of data. Three sets were used for training, and the other three for testing. These sets contained about five thousand samples, which is too many points for practical training, and memory storage. Thus, the sets were thinned by only using every tenth value. This made the sets manageable for training and data storage purposes. The final size of the sets averaged about 500 test points. This leaves an average of 4 or 5 steps from each of the 116 paths, which is a tenth of the original size.
Figure 7.4 Figure 6.4: Normalized Map of Test Path End Points (in the robot workspace)
This particular configuration was chosen to maintain some order in the selection of the points. A random point generator could have been used, but this would have introduced a potential error factor related to path end-point distribution. The entire work space is used as well; this ensures that long and short paths will be generated out of the test data. The different methods for determining optimal paths will de discussed in later chapters.
Figure 7.5 Figure 6.5: Flowchart for Illustration of Selection of Training/Testing Data
7.7 6.7 Training the Neural Network:
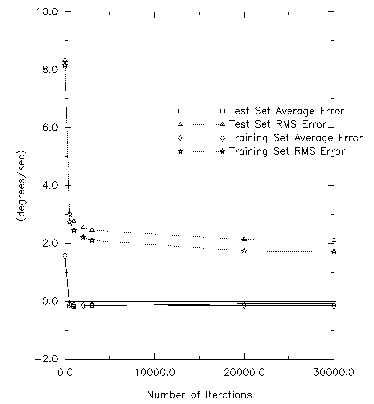
Learning algorithms are still a current topic in neural networks. Therefore, it was decided, not to make the training time an issue for this thesis. As a result the networks were all trained with an excessive number of iterations. The figure below shows that the learning for the maximum velocity controller had converged after a few thousand iterations were completed. The actual training of the networks was done with at least 30,000 iterations. This means that the accuracies presented are the best accuracies obtainable with current training methods.
Figure 7.6 Figure 6.6: Network Training Convergence (The curve shows the convergence of the Maximum Velocity network as it was trained. It shows that Convergence has occurred after a few thousand iterations)
The method for training was, first, to test the network for convergence, based upon the training and test sets (the convergence estimation procedures are described below). The set would then be trained for a thousand, or more, iterations, and the convergence would be remeasured with the training and testing sets. This was continued until the convergence measure stopped decreasing. If the convergence values for the training set were comparable to the testing set, then the network was said to have converged, and generalized.
7.8 6.8 Estimation of Neural Network Training Convergence:
To estimate the training convergence of a neural network it is necessary to arrive at a mathematical value of agreement between the ideal outputs, and actual network outputs. It was decided that simple statistical measures could yield adequate results.
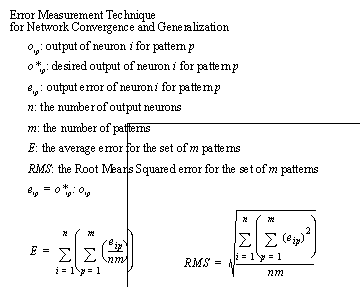
The values in the training and testing sets are network inputs, and the expected network outputs. It is possible to apply a set of inputs to the network, and then find the network output. The network output may then be directly compared to the desired value to obtain an ‘error’. When all the points in the data set are compared to the network, the ‘error’ sample size becomes large, and the statistics become reliable. These comparisons should give an estimate of agreement between the training set and the actual neural network response.
The main concerns in neural network training are convergence and generalization. Convergence is a measure of how closely the trained network matches the desired values of the training set. Generalization is a measure of how consistently the training and testing sets are matched. A good measure of closeness (Convergence) is the average of the errors. The Root Mean Squared (R.M.S.) method [Devore, 1982] provides a good measure of generalization and convergence. The procedure of using RMS for neural network error evaluation was suggested by Yeung and Gekey [1989]. When measuring average joint angle errors, all errors were measured for all joints for the entire training set. The errors are expressed as both an average and RMS values (as seen below). The average error is mostly a curiosity, and has little relevance to the results, except to show that the average error is about zero.
Convergence may be measured in two ways (please refer to formulas below). First, when the R.M.S. error has ‘leveled-off’ the system is stable, and may be said to have converged. The degree of convergence is a measure of how close the R.M.S. error is to zero.
Generalization is easily determined by comparing the R.M.S. of two independent data sets. If the sets have similar R.M.S. values, then the network may be said to have found a good general solution to the problem.
7.9 6.9 Summary:
Neural Networks have many advantages that make them fast, robust, and adaptive ‘black boxes’.
The frequency of the controller must be higher than the natural, or resonant frequencies of the robot.
If the controller must use time based input (like derivatives), they are best done outside the controller.
Velocity profiles may be used for motion planning by imposing a few rules.
A neural network with 20 hidden neurons, and a bias input, will be used for this thesis.
Two sets of data will be used to train and test the neural network.
Data sets (of trajectories) will be generated from points distributed in space.
R.M.S. error may be used to estimate convergence and generalization.