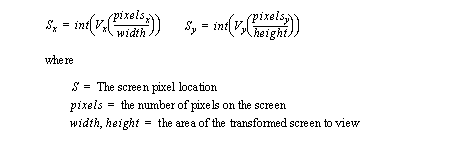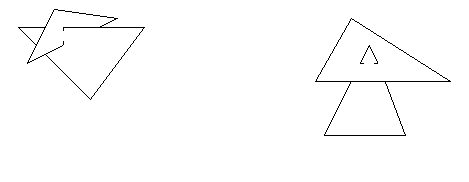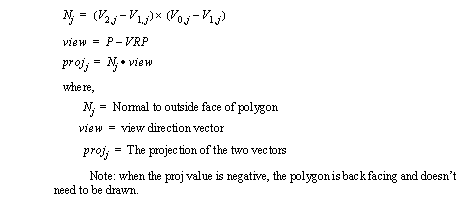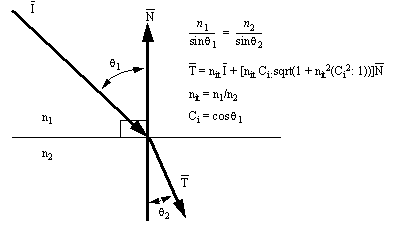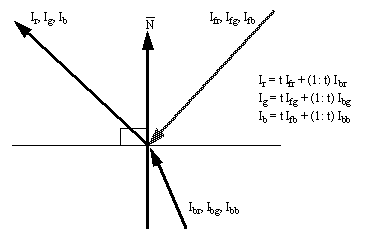9. Mathematical Elements of Computer Graphics
• To put geometries on the computer screen we depend on basic mathematical tools and methods.
• After a geometric model is constructed, it must be displayed (rendered).
• Rendering is mainly limited by computer hardware, and the geometric model.
• The main methods for doing computer graphics are,
Wire Frame
Wire frame with hidden line removal
Polygon drawing (backface, and clipping)
Shaded polygons
Raytracing
• As the scene becomes more complicated, the computing time becomes longer, but the picture becomes more realistic.
• The basic history of research on geometric modeling can be summarized as,
2D computer drafting: Mid 60s
2.5 D: Late 60s
3D Wire Frame Systems: Early 70s
3D Surface Systems: Mid 70s
3D Primitive Solids: Early to Mid 70s
3D Arbitrary Solids: Mid to Late 70s
9.1 Pixels
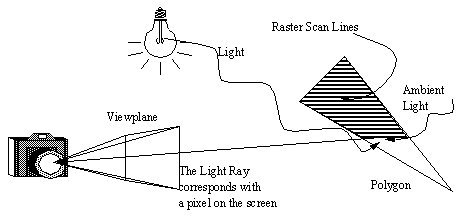
• The fundamental task is converting lines, points and surfaces in 3D space, to be depicted on a 2D screen using colored pixels, or printed on paper with dots, or plotted with pens.
• A computer screen is made up of an square array of points (pixels). The points can be lit up. When viewed as a whole these points make a picture.
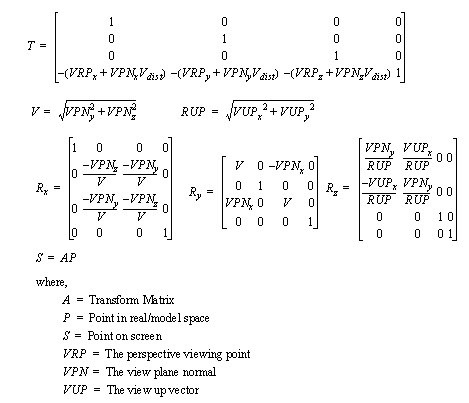
• One major problem is making a map between a geometry model (a collection of points) and what we see on the screen. This is accomplished with the perspective transform.
9.2 The Perspective Transform
• A set of basic viewing parameters may be defined (variations are also common),
The point the Eye is looking at, and from which direction
The focal distance to the viewing plane
The size of the viewing plane being focused on
Which direction is up for the eye
• As seen above the viewing parameters can all be combined using simple matrix multiplication which will convert a point in 3D space to a point on the screen.
• The process of drawing an object is merely applying this transformation to each point in the 3D model, then using the resulting (x, y) point on the 2D screen. (Note: If this transformation is done properly then z = depth in the view plane.)
• The point mapped to the computer screen can then be converted to a single pixel using a simple scaling calculation. (Note: It is not shown, but if a point is off the screen, then it cannot be drawn.)
• Visual display can be done using,
CRT monitors with Frame Buffer memory to store the image.
plotters which draw one line at a time
printers using special and proprietary graphics languages
• For the sake of simplicity, the remaining graphics methods ignore some trivial operations such as screen coordinates, line clipping at edge of screen, etc.
• The ‘z’ value after the perspective transform gives a relative depth of a point. This can be used later for depth sorting, or to set light intensity to cue the user to view depth.
9.3 Line Drawing
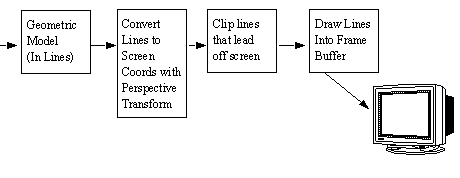
• A wireframe object is simply rendered using the lines (straight, and curved) in a geometric model, then it is converted to screen coordinates using the Perspective Transformation.
• The process is as pictured below,
• If the geometric model is in some other form, such as CSG (Constructive Solids Geometry), it may have to be converted to lines before it may be used.
• Advantages,
Very fast, allows real time manipulation
Easy to see features normally hidden
Supported by almost all computer technology
This display method works with most displays
• Disadvantages,
Drawings can become very crowded, very fast
Hard to visualize solid properties
• Almost all computer graphics packages offer a wireframe display option.
9.4 Hidden Lines
• While the results seem similar, this method requires more sophisticated algorithms.
• Polygons must be used for surface representation.
• The diagram below shows the basic steps in the method of rendering
• Advantages,
similar advantages of wireframe
overcomes the drawing crowding
can be simplified if polygons do not overlap
• Disadvantages,
Consumes more computer time
Does not support simple elemental geometric models
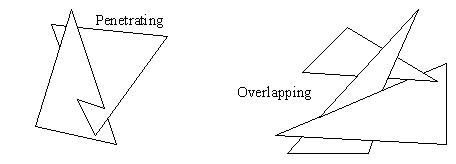
• Clipping algorithms may be difficult, and often use tricks like subdividing polygons into triangles. (There are only 5 cases to consider with overlapping triangles)
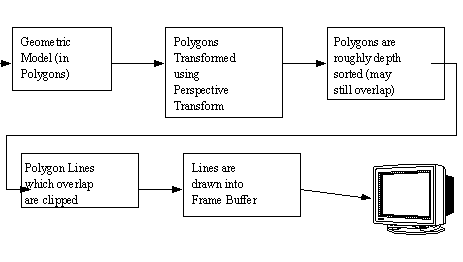
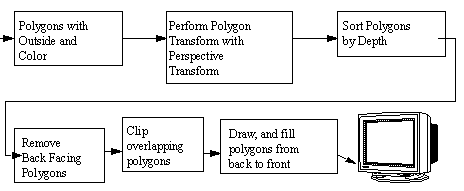
9.5 Polygon Drawing
• This method bears similarities to the hidden line method. The polygons are still depth sorted, but now polygons are filled, and back facing polygons are removed.
• The basic method is as shown below,
• Sorting polygons by depth is basically a function of finding the general center, and then drawing the rear most polygons first.
• A backfacing polygon can be eliminated by calculating its surface normal. The normal is then compared to the viewing axis. If there is more than 90deg between them the polygon doesn’t need to be drawn. (Note: this method assumes that vertices are defined in a counter clockwise order for the outside surface).
• The above diagram only talks about overlapping polygons, but penetration is an equivalent problem.
• Advantages,
with color added, objects look more real.
still relatively easy to implement, and run quickly.
• Disadvantages,
doesn’t suit all computer equipment (eg. laser printers).
surfaces must have outside defined and surfaces must be closed.
• Fill Algorithms generally look at a polygon on the screen, and fill the inside with pixels of a specific color.
• Clipping can also be done by a technique called Z-Buffering, using extra graphics memory. An extra byte is used to store the depth of a pixel when it is calculated. If a new pixel is chosen, it overwrites the last.
******** Include figure for inside/outside test
9.6 Shaded Polygons
• This method is identical to the previous method, except a polygon will be filled with pixels of varying color, which makes the object appear more real.
• A Light Source(s) is defined for a picture. The light has a specific color, direction, distance, etc.
• Ambient light (background, non-direct) also plays a part.
• The color of a pixel will change with the angle of the polygon to the light, the distance from the light, the color of the light, etc.
• Advantages,
the solid begins to look like cartoons, or paintings
still simple to understand and implement
• Disadvantages,
can be slow
requires shaded image display capabilities
• Many Shading methods can be used to give different approximations of light,
Goroud shading
Phong shading
9.7 Colors
• It has been long know that the eye can be tricked into seeing a wide range of colors by blending three different colors in different intensities.
• In the additive color scheme we add red blue and green (RGB). We start with black and add shades of these colors.
• In the subtractive color scheme we start a white pixel. The intensity is reduced by filtering the colors magenta, cyan and yellow.
• Most computers use the RGB scheme, but the subtractive color scheme is popular in printing and photographic reproduction techniques.
• Some of the techniques used when limited numbers of colors or shades are available are,
colors maps
dithering
9.8 Color Maps
• A color map is a list of colors that the computer can use to draw with.
• The eye is very sensitive and can sense millions of different colors. And current trends are to go to 24 bit color systems that have 8 bits for each primary color. This gives the ability to display different colors so close that the human eye cannot detect the difference.
• For various reasons we will use machines that have limited numbers of colors available (256 is common).
• When this occurs colors that should look like smooth transitions tend to look more like bands of color.
• One approach to providing colors is to construct a well distributed pallet (a fixed set of colors) that the user can select from. They must always find the best match to their desired colors.
• The eye tends to be more sensitive to certain colors, and so one approach is to map the colors into a pallet using color bit assignments. For example for a pallet of 256 (8 bits) we may choose to assign 3 bits to blue, 3 bits to blue and only 2 bits to red. This means that there will be 8 intensity levels for both green and blue, but only four for red.
• When using a pallet the some colors will be overused, and other may never be used.
• Another useful approach is to quantize the color map so that it has the best coverage of the desired colors, and lower coverage of unused colors. This process is called quantization.
9.8.1 Quantization with an Octree RGB Cube
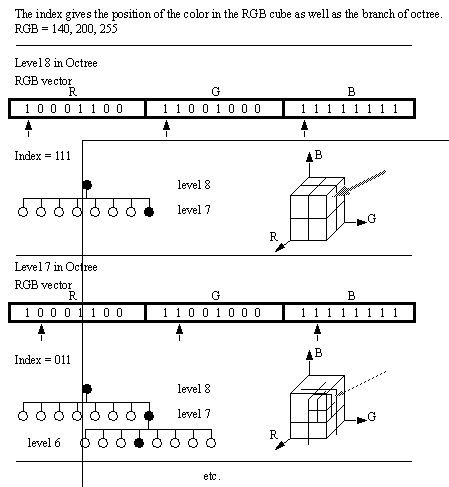
• In the octree quantization method [Graphic Gems by Andrew Glassner] the RGB color information is read sequentially from an input data file. The first k different colors are used as initial entries to the color table. If another color is added so that there are now k+1 colors, some very closely related colors are merged into one and their mean is used as the entry in the colormap. This procedure is repeated for each additional color.
• The RGB cube can be represented by an octree of depth eight by recursive subdivision of the RGB cube. The RGB values (0: 255) are coordinates into the RGB cube. The bit pattern, corresponding to the same level in the octree as the bit position, can be used as the index for the branch into the octree.
Figure 9.1 Figure 20: Mapping an RGB Value into the RGB Cube/Octree
9.8.2 Algorithm and Implementation
• The algorithm has the following three phases:
• Phase 1. Evaluation of Representative Colors
The first step to read the input data and insert colors into leaves of the octree.
InsertTree(Tree: Octree; RGB: Color);
begin
if Tree = NIL
then Make_and_Initialize_New_Node;
if Leaf
then
begin
{Update the number of represented pixels}
inc(Tree^.ColorCount);
{Sum the color values}
AddColors(Tree^.RGB,RGB)
end
else
InsertTree(Next[Branch(RGB)],RGB);
end
The next step is to combine successors of an intermediate node to one leaf node if there are more than the number of colors permitted in the colormap. Closest neighbors are found by putting the position of each leaf node in the octree into a linear list in sorted order and then finding leaves belonging to the same parent node. This is done by masking out the bits below a given parent node level and then finding a parent node with two or more children.
ReduceTree(Tree);
begin
{Find a reducible node}
GetReducible(Tree);
Sum := (0,0,0);
Children := 0;
for i : integer := 0,7 do
if Next[i] <> NIL
{There is an ith successor}
then
begin
Children := Children + 1;
AddColors(Sum,Tree^.Next[i],RGB);
end;
Tree^.Leaf := True;
{Cut the tree at this level}
Tree^.RGB := Sum;
{The node represents the sum of all color values of its children}
Size := Size: Children + 1;
end
Filling the color table
The k leaves of the octree contain the colors for the color table (RGB/Color Count). The colors are written to the table by recursively examining the octree and the index to the colormap is stored in the node.
Mapping the original colors onto the representatives
The image is read a second time using the RGB values stored in an array. For each color in the input, the representative color in the octree is found and its index to the color table is returned.
Quant(Tree: Octree; Original_Color: Color): index;
begin
if Leaf
then
return Tree^.ColorIndex
else
Quant(Tree^.Next[Branch(Orignial_Color)],Original_color);
end
9.8.3 Color Quantization Data Structures
• The following structure for an octnode is the basic structure used for mapping RGB values into the octree:
structure octnode{
int leaf,
colorcnt,
colorindex,
level,
sumR,
sumG,
sumB;
struct octnode *next[8];
}
level is the level of the node in the octree,
leaf indicates whether the node is an interior node in the octree or a leaf node,
If the node is a leaf node,
colorcnt counts the number of input colors that have been mapped to the node,
sumR, sumG, and sumB are the sums of the color components of the colors that have been mapped to the node,
colorindex is the index assigned to the color in the node when the colormap is made.
• Each node holds pointers to eight children. If the node is a leaf node, these pointers must be NULL pointers.
• A list is used to hold octree positions for the representative colors in the colormap. The list is sorted in ascending order to facilitate finding the most closely related colors when it becomes necessary to reduce the number of colors to the maximum size allowed in the colormap.
list[256]
• The colormap is a 3 by 256 array to hold the red, green, and blue color intensities.
colormap[3][256]
• When colors are to be displayed, the color intensities for the pixels are obtained with an index into the colormap. The module which displays the ray tracer image also uses this data structure.
• The RGB color vectors formed when reading the color intensities from the input file into the color quantizer are stored in an array:
pict[]
• The color vectors are used initially as representative colors to establish the colormap and a second time to obtain the indices for the original colors.
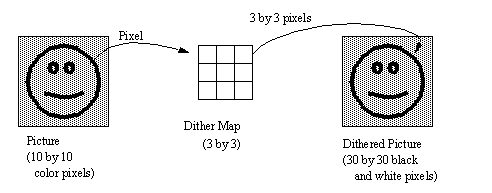
9.9 Dithering
• Sometimes we want to display color images in black and white. (a very common use is when printing shaded images).
• The average pixel is composed of the Additive colors Red-Green-Blue (RGB)
• We assume that the intensity (brightness) of the RGB value can be used as a reasonable approximation. Unfortunately, colors like RED and BLUE may appear to be the same with this method.
• The intensity is then used to set a few pixels ON or OFF in a grid. This is assuming a Black, and White device.
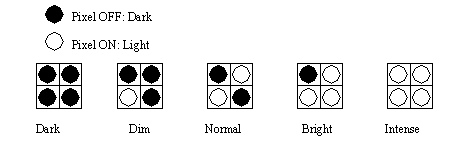
• Say the Dither Map is 2 by 2, In this scheme there are 5 different intensity levels.
• In dithering the dot patterns are made to be at 45 degree angles. This is because if the pattern were horizontal, or vertical, the human eye would detect the repeated pattern easily (this is also done with newspaper pictures).
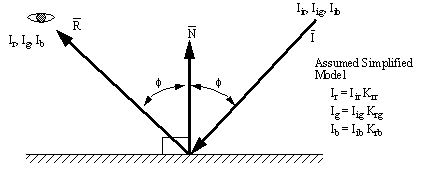
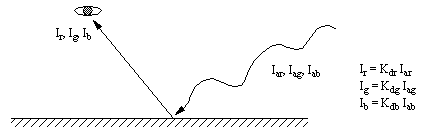
9.10 A Model for Light Ray Reflection
• When light strikes a surface it is often reflected. The reflection model is quite simple. In this case a simple fraction of the incoming light will be used. More sophisticated models may be constructed using information about particular materials.
Reflection of an Incident Light Beam
9.11 A Model for Light Ray Refraction
• When light enters or exits material, its path changes. There are also optical adjustments based on the transparency of the specific material. The path change is determined by Snell’s law, and the change in optical properties are considered by a simplified formula.
Figure 9.2 Refraction of an Incident Light Beam
• After the collision vector has been calculated, the object’s transparency must be taken into account. This is done by using a transparency coefficient ‘t’. When ‘t’ has a value of 1 the object is opaque, and all light originates from the surface. If the object has a ‘t’ value of 0, then all light is from refraction.
Figure 9.3 Light Transmission in the Presence of Transparency
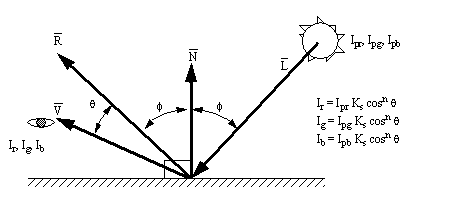
9.12 A Model for Specular Reflection of Point Light
• The highlights which often appear on an illuminated object can be estimated also. In this case the Phong model is used. This model includes an estimate of how ‘fuzzy’ the light patch appears. This is not done if the collision point lies in a shadow.
Specular Reflection of Light
9.13 Ray Tracing
• This method no longer uses polygons, but relies directly on the geometrical model.
• The lines of light which make up the pixels of the picture, are back traced, and followed through reflection, refraction, and ambient light.
• This method generates a horrendous number of calculations.
• The figure on the next page shows how ray tracing is done for the first bounce, many other bounces may be performed for more realism.
• Advantages,
Realistic texture and appearances are easy to use
This is the only display method suited to rendering curved surfaces
The images give photograph quality
• Disadvantages,
Incredibly Slow due to large number of calculations
Requires a very powerful computer
• Support technology is being produced at a tremendous rate.
• Currently used for producing pictures and videos for sales marketing, etc. Many commercials on TV are produced with this method. Used in movies, like Terminator2, the Abyss, etc.
9.13.1 Basic Ray Tracing Theory
• The theory of ray tracing has two basic concerns. Firstly, the light path is of interest, secondly the light transmitted is also of interest. These both involve interactions with real objects, thus light-object interaction must also be covered in this section. Note that in most models discussed the geometric relations are not given. Almost all of these relations are given, derived from other sources, or easily obtained with dot products.
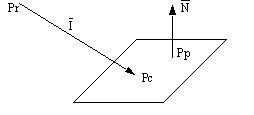
9.13.1.1 - A Model for Diffuse Reflection of Ambient Light
• Ambient light is assumed to be evenly distributed over the entire volume of space. This naturally occurring light will provide a basic level of illumination for all objects.
Figure 9.4 Diffuse Ambient Lighting of A Surface
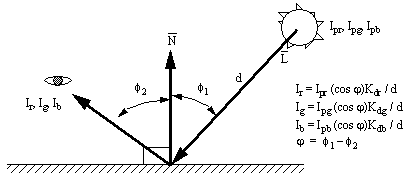
9.13.1.2 - A Model for Diffuse Reflection of Point Light:
• Point lighting is somewhat more sophisticated than Ambient lighting. In this case the direct light will illuminate the surface. The effect is approximated using the angle to the light source, and some constants (based on material properties) to estimate the ‘brightness’. Please note that this calculation is not done if the collision point lies in a shadow.
Figure 9.5 Diffuse Lighting of a Surface with a Point Light Source
9.13.1.3 - Collision of a Ray with a Sphere:
• The method for finding the intersection between a ray and a sphere has been covered in “An Introduction to Ray Tracing” by Glassner [1989]. Therefore, the method will only be reviewed briefly. The method is quite simple because the relationship may be explained explicitly. To state the description in the book:
i) Find distance squared between ray origin and center,
ii) Calculate ray distance which is closest to center,
iii) Test if ray is outside and points away from sphere,
iv) Find square of half chord intersection distance,
v) Test if square is negative,
vi) Calculate intersection distance,
vii) Find intersection point,
viii) Calculate normal at point.
• This algorithm gives at worst 16 additions, 13 multiples, 1 root, and 3 compares.
9.13.1.4 - Collision of a Ray With a Plane:
• A method for ray plane intersection was used to find collisions with the checkerboard. This method was devised from scratch. The proof will not be given, but it involves a parametric representation of the line, which is substituted into the plane equation. The parameter value was then found, and the collision point calculated. The algorithm for Line: Plane intersection is given below:
Figure 9.6 A Ray Colliding with a Plane
i) The dot product between I and N is found,
ii) If the dot product is greater than, or equal to, zero then the line does not intersect the plane,
iii) The line-plane intersection parameter is calculated (the dot product may be used here),
iv) The intersection point is calculated.
• This algorithm is also based on an explicit relationship, therefore it is quite fast. In the best case there are 3 multiplies, 2 adds and 1 compare. In the worst case there are 12 multiplies, 1 divide, 10 adds/subtracts.
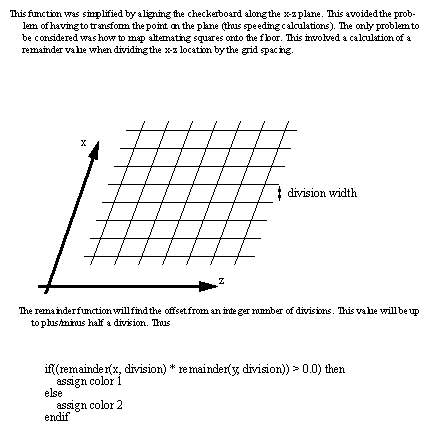
9.13.1.5 - Mapping a Pattern
• When we are rendering images we quite often will try to add a texture or pattern to the surface. This can be done by having a separate splines model of the object. While rendering the parametric model is interrogated as each surface point is being rendered.
• A simple example is the mapping of a checkerboard pattern on a plane using a function.
.
Figure 9.7 A Surface with a CheckerBoard Pattern
9.13.2 Ray Tracer Algorithms
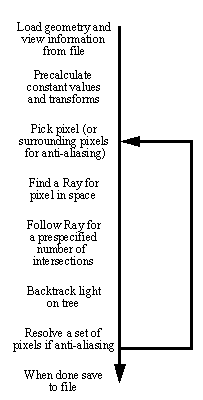
• This ray tracer will backtrack rays, and follow their paths through space. This involves a basic set of functions. First the general algorithm description is given for ray tracing, in general,
Figure 9.8 Basic Order of Higher Level Ray Tracer Features
• This structure involves performing as many calculations as possible before execution begins. Although not all calculations are done before, some tricks will be described below which greatly improve the speed of ray tracing.
• The process of filling up the image has multiple approaches. If a simple image is needed, then a simple scan of all the pixels can be made. An anti-aliasing technique requires oversampling of the pixels. When a pixel is chosen, the pixel must be mapped to a ray in space. This ray may be considered on a purely geometrical basis.
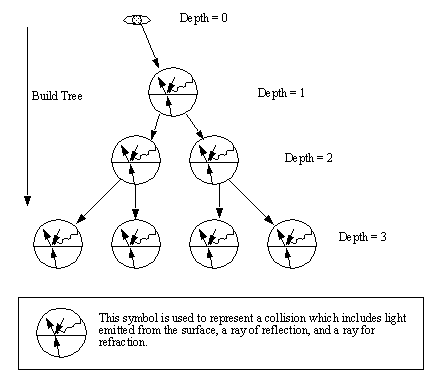
• When backtracking rays in space, they will either hit an object, or take on the background color. If an object has been hit by a light ray, it can either reflect or refract, and it will take on the optical properties of the surface. This leads to a tree data structure for the collisions.
Figure 9.9 The Basic Concept of Back Tracing Rays
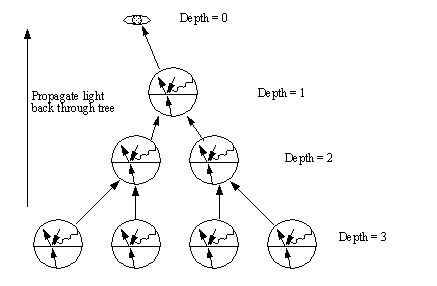
• As seen in Figure above, the light rays may be followed, but the only colors (color explanation follows later) attached to any nodes in this tree are the diffuse lighting from ambient and point sources, and also the specular reflection. After the tree has been fully expanded, the light may be traced forward to the eye. The figure shows the light being propagated back up the tree to the eye (screen pixel).
Figure 9.10 The Basic Concept of Back Tracing Light Values in a Ray Tree
• This structure gives rise to a tree based on a linked list. Each node in the linked list has:
Forward and back pointers,
Surface normals, and optical properties for refraction (used for backtracking),
The lighting from diffuse and specular sources,
Vectors for before and after reflection and refraction,
Positions for ray origins and collision points,
The depth in the search tree,
The identification of which object the ray has come from and has hit.
• All of these properties are used in a dynamic fashion, and the list may be grown until all branches have been terminate (i.e. hit background) or are at the maximum search depth.
• This Ray tree structure is constructed with the data stored in a second structure. The second structure for scene data contains geometric information:
Objects for each ball including centers, radii, and ordered lists of the closest ball,
An object for the floor, eye, and light, including positions, orientations, and a list of balls, ordered from closest to farthest,
Transformation matrices,
The same perspective parameters used in the user interface,
A list of picture areas only filled with background light,
Optical properties for balls, and floor: index of refraction, and shininess, transparency, diffuse, Phong, and specular constants,
The maximum ray tree depth,
Precalculated values for use in the program.
• Both of these groups of data items have been ‘lumped’ together in separate data structures. As mentioned before the rays are organized as a linked list. The geometric information is stored in a second structure. By using this approach it makes it very easy to pass the various classes of information around the system, without pushing large numbers of variables on the stack.
9.13.3 Bounding Volumes
• Bounding test volumes were set up, but these have proven to be ineffective in most cases where the scene is filled, their only benefit is in a nearly empty scene, where they save a ray calculation for every pixel. There are two main bounding volumes. The first volume is constructed around the set of balls. The second is constructed to represent the half of the screen which the floor will be displayed in (this could be all or none).
9.13.4 Shadows
• Within the image there are certain objects which will be in shadows. In these cases there is a reduction in the amount of light. To detect this case a ray is traced between the light, and the point of interest (the only objects which will be hit here are spheres). If the light hits any spheres, the shadow is confirmed. When a shadow is confirmed, the specular reflection, and diffuse lighting from a point source are ignored.
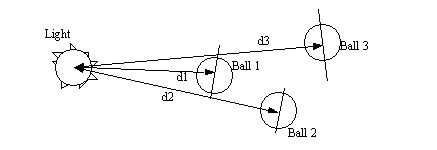
• To speed the checking process, the balls have been ordered by their distance from the light. The balls are checked in order, until one is hit, or the distance from the ball is greater than the distance between the point and the light.
Figure 9.11 Depth Ordered Balls
• In the figure above there are a set of balls ordered by depth from the light source. If we are looking for a shadow on any point of Ball 2, we first find a vector from the point to the light. The search then begins backward from the light. If the light strikes Ball 1, then Ball 2 is in its shadow. If the light misses it then Ball 2 is not in a shadow. Say we are finding a shadow on the floor, and the floor is known to be some distance (from the light) between Ball 1 (d1) and Ball 2 (d2). The algorithm would check for collisions with Balls 1 and 2. A check would reveal that the distance for d2 is greater than the distance to the floor, and since, no balls will have been hit, it may be concluded that the floor is not in a shadow, and the search is discontinued. This can save a great deal of search time when the light is close to the floor.
9.13.5 Aliasing
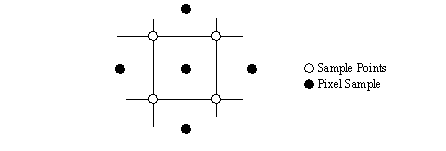
• A problem with ray tracing is that features smaller than a pixel can be missed. Another problem is that features not aligned to the pixel grid become choppy. A method for solving this problem is Super-sampling Anti-aliasing. This uses an approach where the pixel map is sampled normally, as well as between pixels, and the pixel values are combined.
Figure 9.12 Sample Points for Anti-aliasing
The black points in Figure 18 are sampled, the four points around it are used to adjust the value. This will tend to give a local averaging effect which overcomes sudden discontinuities in image space.
9.13.6 Advanced topics
• Some advanced topics include,
Pattern and texture mapping,
Fog and lighting effects,
Multiple light sources,
Splines as primitives,
Estimates of non-point light sources,
New primitives,
9.14 ADVANCED GRAPHICS TECHNIQUES
9.14.1 Animation
• To simulate motion we collect a set of still frames of a rendered object being translated and rotated. These are played back to simulate the motion.
• The paths of motion may be defined using splines, equations, functions, etc.
• Some tricks used for doing animation are,
Only drawing the part of the screen that is changing
Blurring images for fast moving objects reduced the flicker.
Alternating two pictures (double buffering). While one picture is being drawn, the previous picture is displayed.
• Buffer swapping gives smooth looking graphics by:
i) Swapping the screen with a memory block,
ii) Erasing the previous image (within a bounding box),
iii) Redrawing the image,
iv) Repeat the loop.
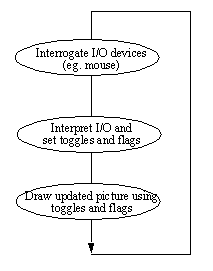
• When using interactive animations a program structure is required that separated user inputs from rendering.
• The first program loop examines inputs and user requests from the mouse, keyboard, etc. Based on these values we reset internal flags and registers.
• Based on the values of the internal registers the drawing is updated.
• During execution, the program loops through both of these operations, and thus provides a separation between simultaneous control, and display motion.
• With this architecture it is easy to add ‘real time’ control functions.
9.15 References
9.1 Chang, T-C., Wysk, R.A. and Wang, H-P., Computer-Aided Manufacturing, Second Edition, Prentice Hall, 1998.
9.2 Foley, J., Van Dam, A., “Fundamentals of Interactive Computer Graphics”, Addison Wesley, 1984.
9.3 Glassner, A.S., “An Introduction to Ray Tracing”, Academic Press, 1989.
9.4 Glassner, A.S., “Graphics Gems”, Academic Press, 1990.
9.5 Harrington, S., “Computer Graphics: A Programming Approach”, McGraw Hill, 1983.
9.6 Rogers, D.F., Adams, J.A., “Mathematical Elements for Computer Graphics”, McGraw Hill, 1990.
9.16 Problems
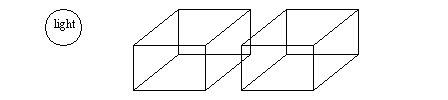
Problem 9.1 Given the geometry below, draw how it would appear with 5 different computer graphics techniques.