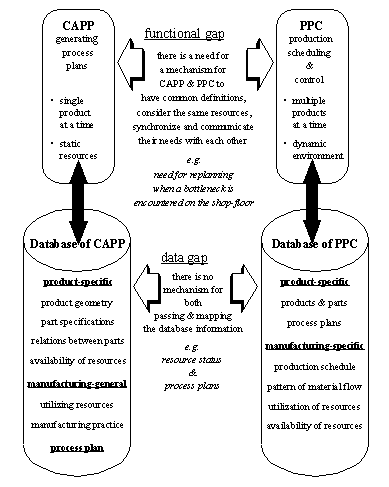
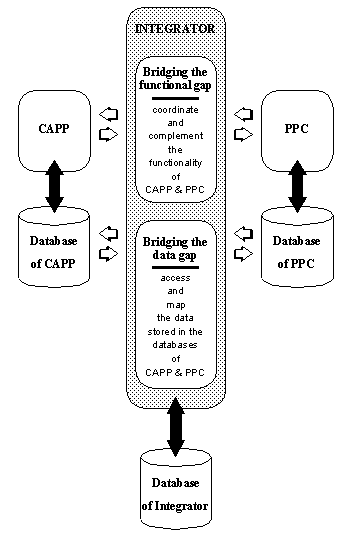
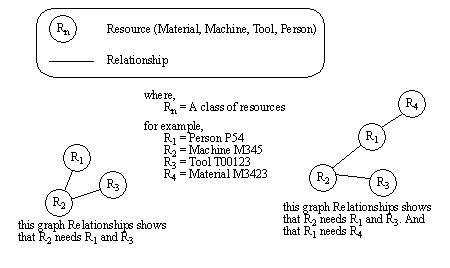
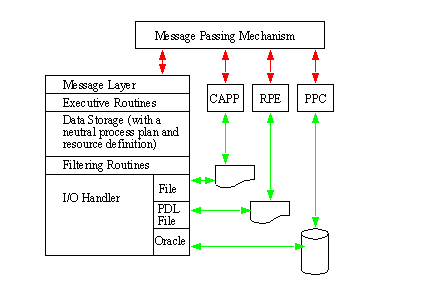
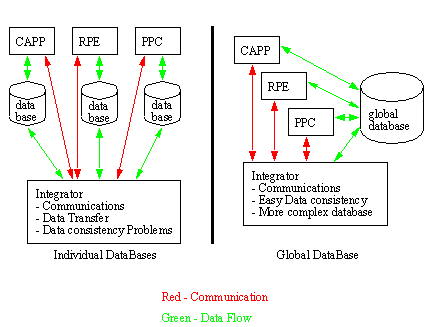
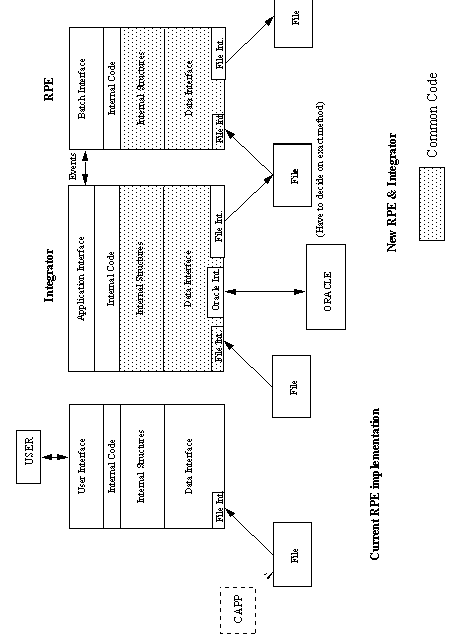
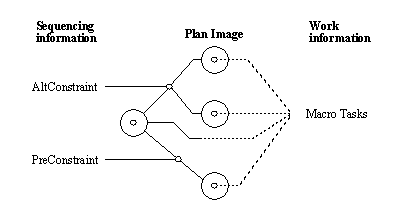
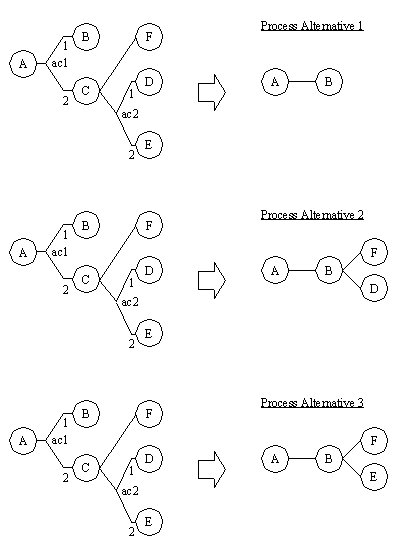
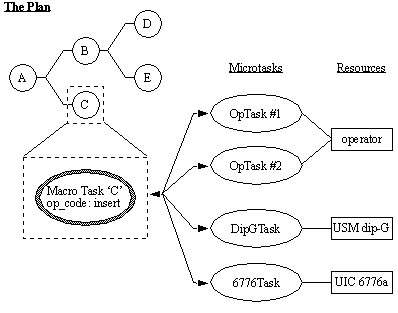
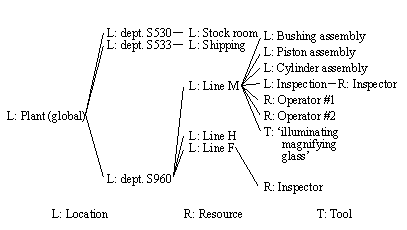
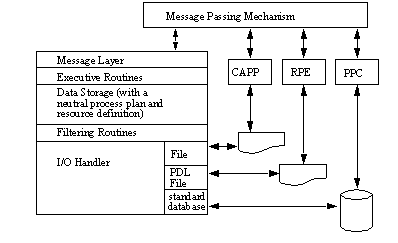
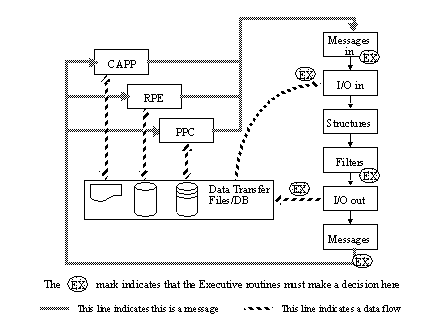
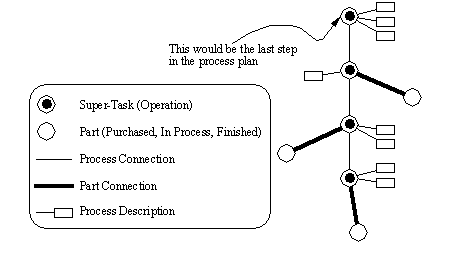
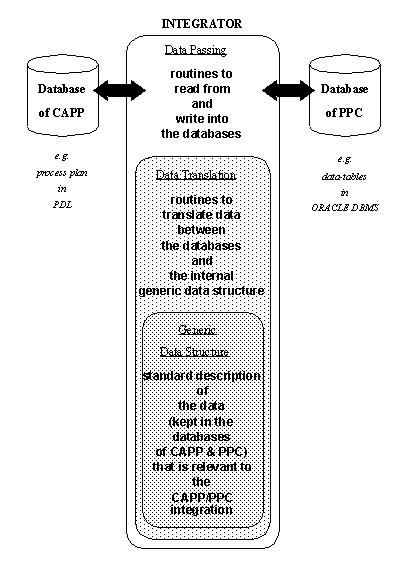
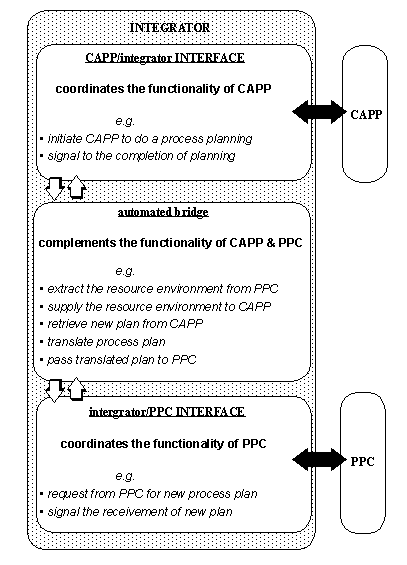
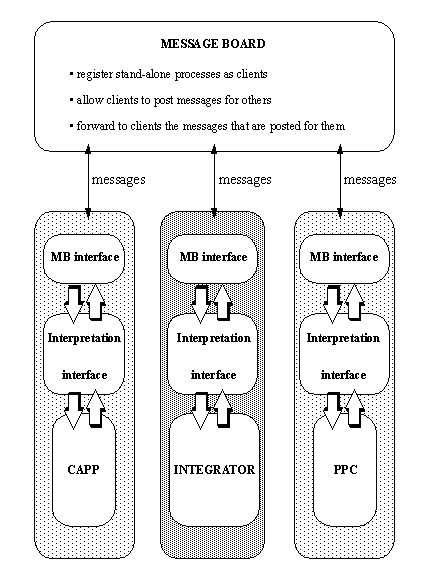
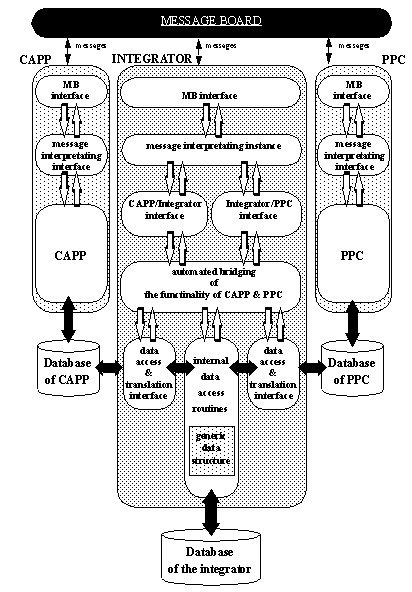
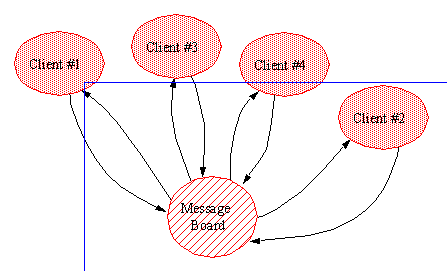
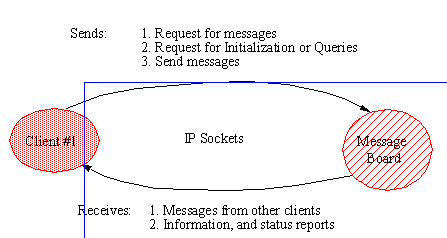
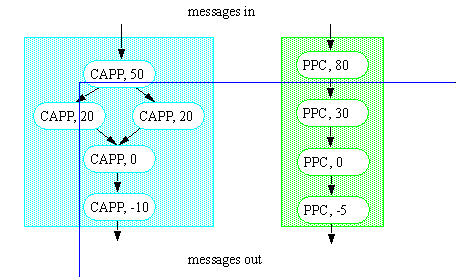
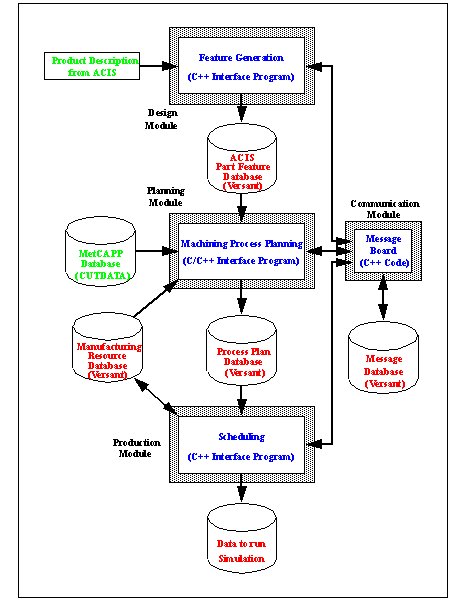
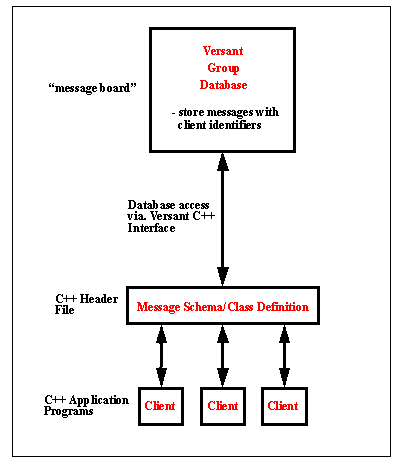
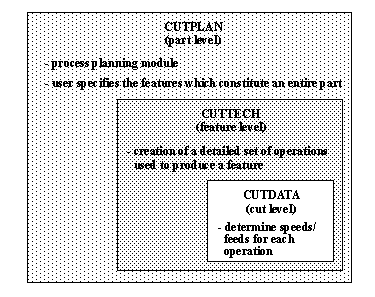
APPENDIX A : ORACLE INTERFACE FOR COMMON DATA
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <math.h>
#include "data.h"
#include "read_data_stub.h"
EXEC SQL BEGIN DECLARE SECTION;
varchar uid[20] ;/* user id */
varchar pwd[20] ;/* password */
int id ;/* id */
varchar nam[100] ;/* name */
varchar dscr[100] ;/* description */
int usage_ofr ;/* usage offered */
int util_ftr ;/* utility factor */
int logical_x ;/* logical x-coord */
int logical_y ;/* logical y-coord */
int prod_seg_01 ;/* product segment */
int prod_seg_02 ;
int prod_seg_03 ;
int prod_seg_04 ;
int prod_seg_05 ;
int prod_seg_06 ;
int prod_seg_07 ;
int prod_seg_08 ;
int prod_seg_09 ;
int prod_seg_10 ;
int prod_seg_11 ;
int prod_seg_12 ;
int prod_seg_13 ;
int prod_seg_14 ;
int prod_seg_15 ;
int prod_seg_16 ;
int prod_seg_17 ;
int prod_seg_18 ;
int prod_seg_19 ;
int prod_seg_20 ;
int prod_seg_21 ;
int prod_seg_22 ;
int prod_seg_23 ;
int prod_seg_24 ;
int prod_seg_25 ;
int prod_seg_cnt ;/* product segment count */
int resrce_prt_01 ;/* resoruce part */
int resrce_prt_02 ;
int resrce_prt_03 ;
int resrce_prt_04 ;
int resrce_prt_05 ;
int resrce_prt_06 ;
int resrce_prt_07 ;
int resrce_prt_08 ;
int resrce_prt_09 ;
int resrce_prt_10 ;
int resrce_prt_11 ;
int resrce_prt_12 ;
int resrce_prt_13 ;
int resrce_prt_14 ;
int resrce_prt_15 ;
int resrce_prt_16 ;
int resrce_prt_17 ;
int resrce_prt_18 ;
int resrce_prt_19 ;
int resrce_prt_20 ;
int resrce_prt_21 ;
int resrce_prt_22 ;
int resrce_prt_23 ;
int resrce_prt_24 ;
int resrce_prt_25 ;
int resrce_cnt ;/* resource count */
int plan_horiz ;/* planning horizon */
int cost_setup ;/* cost: setup */
int cost_run ;/* cost: run */
int scrap_rate ;/* scrap rate */
int avail ;/* availability */
int class ;/* class */
int capab ;/* capab */
int skill ;/* skill */
int qualf ;/* qualf */
int quant ;/* quant */
int cost_rate ;/* cost: rate */
int setup_time ;/* time: setup */
int usage_time ;/* time: usage */
int cnst_01 ;/* cnst */
int cnst_02 ;
int cnst_03 ;
int cnst_04 ;
int cnst_05 ;
int cnst_06 ;
int cnst_07 ;
int cnst_08 ;
int cnst_09 ;
int cnst_10 ;
int cnst_cnt ;/* constraint count */
int factory ;/* factory */
int db_key ;/* db_key */
int modf_idx ;/* modf_idx */
int unit_m ;/* unit_m */
int s_t_stat ;/* s_t_stat */
int part_id ;/* part_id */
int s_t_consumer ;/* s_t_consumer */
int s_t_supplier ;/* s_t_supplier */
int consumer_num ;/* consumer_num */
int relat_fct ;/* relat_fct */
int id_s_t ;/* id_s_t */
int id_assoc ;/* id_assoc */
int cap_grp ;/* cap_grp */
int resrce_01 ;/* resrce */
int resrce_02 ;
int resrce_03 ;
int resrce_04 ;
int resrce_05 ;
int resrce_06 ;
int resrce_07 ;
int resrce_08 ;
int resrce_09 ;
int resrce_10 ;
int res_cnt ;/* resrce_cnt */
int est_time_run ;/* est_time_run */
int est_time_setup ;/* est_time_setup */
int rank ;/* rank */
int usage_capacity ;/* usage_capacity */
int req_capacity ;/* req_capacity */
int plan_level ;/* plan_level */
int lot_min ;/* lot_min */
int lot_siz ;/* lot_siz */
int avg_stock ;/* avg_stock */
int min_lead_time ;/* min_lead_time */
int relat_quant ;/* relat_quant */
EXEC SQL END DECLARE SECTION;
EXEC SQL INCLUDE SQLCA; /* SQL Communication Area */
/* ********************************************************
init : process plan
******************************************************** */
int pd_init(plans)
PLAN_DATA *plans;
{
static int error;
if((pd_init_cap_grp(plans) == NO_ERROR) &&
(pd_init_resrce(plans) == NO_ERROR) &&
(pd_init_resrce_rel(plans) == NO_ERROR) &&
(pd_init_prt_dat(plans) == NO_ERROR) &&
(pd_init_prt_cntn(plans) == NO_ERROR) &&
(pd_init_proc_dscr(plans) == NO_ERROR) &&
(pd_init_super_task(plans) == NO_ERROR) &&
(pd_init_proc_cntn(plans) == NO_ERROR)){
error = NO_ERROR;
}else{
error = ERROR;
}
return(error);
}
int pd_init_cap_grp(plans)
PLAN_DATA *plans;
{
static int error;
error = NO_ERROR;
plans->ptr_cap_grp = -1;
return(error);
}
int pd_init_resrce(plans)
PLAN_DATA *plans;
{
static int error;
error = NO_ERROR;
plans->ptr_resrce = -1;
return(error);
}
int pd_init_resrce_rel(plans)
PLAN_DATA *plans;
{
static int error;
error = NO_ERROR;
plans->ptr_resrce_rel = -1;
return(error);
}
int pd_init_prt_dat(plans)
PLAN_DATA *plans;
{
static int error;
error = NO_ERROR;
plans->ptr_prt_dat = -1;
return(error);
}
int pd_init_prt_cntn(plans)
PLAN_DATA *plans;
{
static int error;
error = NO_ERROR;
plans->ptr_prt_cntn = -1;
return(error);
}
int pd_init_proc_dscr(plans)
PLAN_DATA *plans;
{
static int error;
error = NO_ERROR;
plans->ptr_proc_dscr = -1;
return(error);
}
int pd_init_super_task(plans)
PLAN_DATA *plans;
{
static int error;
error = NO_ERROR;
plans->ptr_super_task = -1;
return(error);
}
int pd_init_proc_cntn(plans)
PLAN_DATA *plans;
{
static int error;
error = NO_ERROR;
plans->ptr_proc_cntn = -1;
return(error);
}
/* ********************************************************
de-init : process plan
******************************************************** */
int pd_deinit(plans)
PLAN_DATA *plans;
{
static int error;
error = pd_init(plans);
return(error);
}
/* ********************************************************
put : process plan
******************************************************** */
int pd_put_cap_grp(plans, cg)
PLAN_DATA *plans;
CAP_GRP *cg;
{
static int error;
static int ptr;
static int i;
if((cg->prod_seg_cnt < 0) ||
(cg->prod_seg_cnt > 25) ||
(cg->resrce_cnt < 0) ||
(cg->resrce_cnt > 25) ||
(plans->ptr_cap_grp + 1 >= MAX_REC_CAP_GRP)) {
error = ERROR;
}else{
ptr = ++(plans->ptr_cap_grp);
plans->cap_grp[ptr].id = cg->id;
strcpy(plans->cap_grp[ptr].nam, cg->nam);
strcpy(plans->cap_grp[ptr].dscr, cg->dscr);
plans->cap_grp[ptr].usage_ofr = cg->usage_ofr;
plans->cap_grp[ptr].util_ftr = cg->util_ftr;
plans->cap_grp[ptr].logical_x = cg->logical_x;
plans->cap_grp[ptr].logical_y = cg->logical_y;
plans->cap_grp[ptr].prod_seg_cnt = cg->prod_seg_cnt;
for(i = 0; i < cg->prod_seg_cnt; i++){
plans->cap_grp[ptr].prod_seg[i] = cg->prod_seg[i];
}
plans->cap_grp[ptr].resrce_cnt = cg->resrce_cnt;
for(i = 0; i < cg->resrce_cnt; i++){
plans->cap_grp[ptr].resrce_prt[i] = cg->resrce_prt[i];
}
plans->cap_grp[ptr].plan_horiz = cg->plan_horiz;
plans->cap_grp[ptr].cost_setup = cg->cost_setup;
plans->cap_grp[ptr].cost_run = cg->cost_run;
plans->cap_grp[ptr].scrap_rate = cg->scrap_rate;
plans->cap_grp[ptr].avail = cg->avail;
error = NO_ERROR;
}
return error;
}
int pd_put_resrce(plans, rs)
PLAN_DATA *plans;
RESRCE *rs;
{
static int error;
static int ptr;
static int i;
if(plans->ptr_resrce + 1 >= MAX_REC_RESRCE) {
error = ERROR;
}else{
ptr = ++(plans->ptr_resrce);
plans->resrce[ptr].id = rs->id;
strcpy(plans->resrce[ptr].nam, rs->nam);
strcpy(plans->resrce[ptr].dscr, rs->dscr);
plans->resrce[ptr].class = rs->class;
plans->resrce[ptr].capab = rs->capab;
plans->resrce[ptr].skill = rs->skill;
plans->resrce[ptr].qualf = rs->qualf;
plans->resrce[ptr].quant = rs->quant;
plans->resrce[ptr].cost_setup = rs->cost_setup;
plans->resrce[ptr].cost_run = rs->cost_run;
plans->resrce[ptr].cost_rate = rs->cost_rate;
plans->resrce[ptr].setup_time = rs->setup_time;
plans->resrce[ptr].usage_time = rs->usage_time;
plans->resrce[ptr].avail = rs->avail;
error = NO_ERROR;
}
return error;
}
int pd_put_resrce_rel(plans, rr)
PLAN_DATA *plans;
RESRCE_REL *rr;
{
static int error;
static int ptr;
static int i;
if((rr->cnst_cnt < 0) ||
(rr->cnst_cnt > 10) ||
(plans->ptr_resrce_rel + 1 >= MAX_REC_RESRCE_REL)) {
error = ERROR;
}else{
ptr = ++(plans->ptr_resrce_rel);
plans->resrce_rel[ptr].id = rr->id;
plans->resrce_rel[ptr].cnst_cnt = rr->cnst_cnt;
for(i = 0; i < rr->cnst_cnt; i++){
plans->resrce_rel[ptr].cnst[i] = rr->cnst[i];
}
error = NO_ERROR;
}
return error;
}
int pd_put_prt_dat(plans, pd)
PLAN_DATA *plans;
PRT_DAT *pd;
{
static int error;
static int ptr;
static int i;
if(plans->ptr_prt_dat + 1 >= MAX_REC_PRT_DAT) {
error = ERROR;
}else{
ptr = ++(plans->ptr_prt_dat);
plans->prt_dat[ptr].id = pd->id;
strcpy(plans->prt_dat[ptr].nam, pd->nam);
strcpy(plans->prt_dat[ptr].dscr, pd->dscr);
plans->prt_dat[ptr].factory = pd->factory;
plans->prt_dat[ptr].db_key = pd->db_key;
plans->prt_dat[ptr].modf_idx = pd->modf_idx;
plans->prt_dat[ptr].unit_m = pd->unit_m;
plans->prt_dat[ptr].s_t_stat = pd->s_t_stat;
error = NO_ERROR;
}
return error;
}
int pd_put_prt_cntn(plans, pc)
PLAN_DATA *plans;
PRT_CNTN *pc;
{
static int error;
static int ptr;
static int i;
if(plans->ptr_prt_cntn + 1 >= MAX_REC_PRT_CNTN) {
error = ERROR;
}else{
ptr = ++(plans->ptr_prt_cntn);
plans->prt_cntn[ptr].id = pc->id;
plans->prt_cntn[ptr].part_id = pc->part_id;
plans->prt_cntn[ptr].s_t_consumer = pc->s_t_consumer;
plans->prt_cntn[ptr].s_t_supplier = pc->s_t_supplier;
plans->prt_cntn[ptr].consumer_num = pc->consumer_num;
plans->prt_cntn[ptr].relat_fct = pc->relat_fct;
error = NO_ERROR;
}
return error;
}
int pd_put_proc_dscr(plans, pd)
PLAN_DATA *plans;
PROC_DSCR *pd;
{
static int error;
static int ptr;
static int i;
if((pd->res_cnt < 0) ||
(pd->res_cnt > 10) ||
(plans->ptr_proc_dscr + 1 >= MAX_REC_PROC_DSCR)) {
error = ERROR;
}else{
ptr = ++(plans->ptr_proc_dscr);
plans->proc_dscr[ptr].id = pd->id;
plans->proc_dscr[ptr].id_s_t = pd->id_s_t;
plans->proc_dscr[ptr].id_assoc = pd->id_assoc;
strcpy(plans->proc_dscr[ptr].dscr, pd->dscr);
plans->proc_dscr[ptr].cap_grp = pd->cap_grp;
plans->proc_dscr[ptr].res_cnt = pd->res_cnt;
for(i = 0; i < pd->res_cnt; i++){
plans->proc_dscr[ptr].resrce[i] = pd->resrce[i];
}
plans->proc_dscr[ptr].est_time_run = pd->est_time_run;
plans->proc_dscr[ptr].est_time_setup= pd->est_time_setup;
plans->proc_dscr[ptr].rank = pd->rank;
plans->proc_dscr[ptr].usage_capacity= pd->usage_capacity;
plans->proc_dscr[ptr].req_capacity = pd->req_capacity;
error = NO_ERROR;
}
return error;
}
int pd_put_super_task(plans, st)
PLAN_DATA *plans;
SUPER_TASK *st;
{
static int error;
static int ptr;
static int i;
if(plans->ptr_super_task + 1 >= MAX_REC_SUPER_TASK) {
error = ERROR;
}else{
ptr = ++(plans->ptr_super_task);
plans->super_task[ptr].id = st->id;
strcpy(plans->super_task[ptr].dscr, st->dscr);
plans->super_task[ptr].plan_level = st->plan_level;
plans->super_task[ptr].lot_min = st->lot_min;
plans->super_task[ptr].lot_siz = st->lot_siz;
plans->super_task[ptr].avg_stock = st->avg_stock;
plans->super_task[ptr].scrap_rate = st->scrap_rate;
error = NO_ERROR;
}
return error;
}
int pd_put_proc_cntn(plans, pc)
PLAN_DATA *plans;
PROC_CNTN *pc;
{
static int error;
static int ptr;
static int i;
if(plans->ptr_proc_cntn + 1 >= MAX_REC_PROC_CNTN) {
error = ERROR;
}else{
ptr = ++(plans->ptr_proc_cntn);
plans->proc_cntn[ptr].id = pc->id;
plans->proc_cntn[ptr].s_t_consumer = pc->s_t_consumer;
plans->proc_cntn[ptr].s_t_supplier = pc->s_t_supplier;
plans->proc_cntn[ptr].min_lead_time = pc->min_lead_time;
plans->proc_cntn[ptr].relat_quant = pc->relat_quant;
error = NO_ERROR;
}
return error;
}
/* ********************************************************
get : process plan
******************************************************** */
int pd_get_cap_grp(plans, pos, cg)
PLAN_DATA *plans;
int pos;
CAP_GRP *cg;
{
static int error;
static int i;
if((pos < 0)||(plans->ptr_cap_grp < pos)) {
error = ERROR;
}else{
cg->id = plans->cap_grp[pos].id;
strcpy(cg->nam, plans->cap_grp[pos].nam);
strcpy(cg->dscr, plans->cap_grp[pos].dscr);
cg->usage_ofr = plans->cap_grp[pos].usage_ofr;
cg->util_ftr = plans->cap_grp[pos].util_ftr;
cg->logical_x = plans->cap_grp[pos].logical_x;
cg->logical_y = plans->cap_grp[pos].logical_y;
cg->prod_seg_cnt = plans->cap_grp[pos].prod_seg_cnt;
for(i = 0; i < plans->cap_grp[pos].prod_seg_cnt; i++){
cg->prod_seg[i] = plans->cap_grp[pos].prod_seg[i];
}
cg->resrce_cnt = plans->cap_grp[pos].resrce_cnt;
for(i = 0; i < plans->cap_grp[pos].resrce_cnt; i++){
cg->resrce_prt[i] = plans->cap_grp[pos].resrce_prt[i];
}
cg->plan_horiz = plans->cap_grp[pos].plan_horiz;
cg->cost_setup = plans->cap_grp[pos].cost_setup;
cg->cost_run = plans->cap_grp[pos].cost_run;
cg->scrap_rate = plans->cap_grp[pos].scrap_rate;
cg->avail = plans->cap_grp[pos].avail;
error = NO_ERROR;
}
return error;
}
int pd_get_resrce(plans, pos, rs)
PLAN_DATA *plans;
int pos;
RESRCE *rs;
{
static int error;
static int i;
if((pos < 0)||(plans->ptr_resrce < pos)) {
error = ERROR;
}else{
rs->id = plans->resrce[pos].id;
strcpy(rs->nam, plans->resrce[pos].nam);
strcpy(rs->dscr, plans->resrce[pos].dscr);
rs->class = plans->resrce[pos].class;
rs->capab = plans->resrce[pos].capab;
rs->skill = plans->resrce[pos].skill;
rs->qualf = plans->resrce[pos].qualf;
rs->quant = plans->resrce[pos].quant;
rs->cost_setup = plans->resrce[pos].cost_setup;
rs->cost_run = plans->resrce[pos].cost_run;
rs->cost_rate = plans->resrce[pos].cost_rate;
rs->setup_time = plans->resrce[pos].setup_time;
rs->usage_time = plans->resrce[pos].usage_time;
rs->avail = plans->resrce[pos].avail;
error = NO_ERROR;
}
return error;
}
int pd_get_resrce_rel(plans, pos, rr)
PLAN_DATA *plans;
int pos;
RESRCE_REL *rr;
{
static int error;
static int i;
if((pos < 0)||(plans->ptr_resrce_rel < pos)) {
error = ERROR;
}else{
rr->id = plans->resrce_rel[pos].id;
rr->cnst_cnt = plans->resrce_rel[pos].cnst_cnt;
for(i = 0; i < plans->resrce_rel[pos].cnst_cnt; i++){
rr->cnst[i] = plans->resrce_rel[pos].cnst[i];
}
error = NO_ERROR;
}
return error;
}
int pd_get_prt_dat(plans, pos, pd)
PLAN_DATA *plans;
int pos;
PRT_DAT *pd;
{
static int error;
static int i;
if((pos < 0)||(plans->ptr_prt_dat < pos)) {
error = ERROR;
}else{
pd->id = plans->prt_dat[pos].id;
strcpy(pd->nam, plans->prt_dat[pos].nam);
strcpy(pd->dscr, plans->prt_dat[pos].dscr);
pd->factory = plans->prt_dat[pos].factory;
pd->db_key = plans->prt_dat[pos].db_key;
pd->modf_idx = plans->prt_dat[pos].modf_idx;
pd->unit_m = plans->prt_dat[pos].unit_m;
pd->s_t_stat = plans->prt_dat[pos].s_t_stat;
error = NO_ERROR;
}
return error;
}
int pd_get_prt_cntn(plans, pos, pc)
PLAN_DATA *plans;
int pos;
PRT_CNTN *pc;
{
static int error;
static int i;
if((pos < 0)||(plans->ptr_prt_cntn < pos)) {
error = ERROR;
}else{
pc->id = plans->prt_cntn[pos].id;
pc->part_id = plans->prt_cntn[pos].part_id;
pc->s_t_consumer = plans->prt_cntn[pos].s_t_consumer;
pc->s_t_supplier = plans->prt_cntn[pos].s_t_supplier;
pc->consumer_num = plans->prt_cntn[pos].consumer_num;
pc->relat_fct = plans->prt_cntn[pos].relat_fct;
error = NO_ERROR;
}
return error;
}
int pd_get_proc_dscr(plans, pos, pd)
PLAN_DATA *plans;
int pos;
PROC_DSCR *pd;
{
static int error;
static int i;
if((pos < 0)||(plans->ptr_proc_dscr < pos)) {
error = ERROR;
}else{
pd->id = plans->proc_dscr[pos].id;
pd->id_s_t = plans->proc_dscr[pos].id_s_t;
pd->id_assoc = plans->proc_dscr[pos].id_assoc;
strcpy(pd->dscr, plans->proc_dscr[pos].dscr);
pd->cap_grp = plans->proc_dscr[pos].cap_grp;
pd->res_cnt = plans->proc_dscr[pos].res_cnt;
for(i = 0; i < plans->proc_dscr[pos].res_cnt; i++){
pd->resrce[i] = plans->proc_dscr[pos].resrce[i];
}
pd->est_time_run = plans->proc_dscr[pos].est_time_run;
pd->est_time_setup = plans->proc_dscr[pos].est_time_setup;
pd->rank = plans->proc_dscr[pos].rank;
pd->usage_capacity = plans->proc_dscr[pos].usage_capacity;
pd->req_capacity = plans->proc_dscr[pos].req_capacity;
error = NO_ERROR;
}
return error;
}
int pd_get_super_task(plans, pos, st)
PLAN_DATA *plans;
int pos;
SUPER_TASK *st;
{
static int error;
static int i;
if((pos < 0)||(plans->ptr_super_task < pos)) {
error = ERROR;
}else{
st->id = plans->super_task[pos].id;
strcpy(st->dscr, plans->super_task[pos].dscr);
st->plan_level = plans->super_task[pos].plan_level;
st->lot_min = plans->super_task[pos].lot_min;
st->lot_siz = plans->super_task[pos].lot_siz;
st->avg_stock = plans->super_task[pos].avg_stock;
st->scrap_rate = plans->super_task[pos].scrap_rate;
error = NO_ERROR;
}
return error;
}
int pd_get_proc_cntn(plans, pos, pc)
PLAN_DATA *plans;
int pos;
PROC_CNTN *pc;
{
static int error;
static int i;
if((pos < 0)||(plans->ptr_proc_cntn < pos)) {
error = ERROR;
}else{
pc->id = plans->proc_cntn[pos].id;
pc->s_t_consumer = plans->proc_cntn[pos].s_t_consumer;
pc->s_t_supplier = plans->proc_cntn[pos].s_t_supplier;
pc->min_lead_time = plans->proc_cntn[pos].min_lead_time;
pc->relat_quant = plans->proc_cntn[pos].relat_quant;
error = NO_ERROR;
}
return error;
}
/* ********************************************************
print : process plan
******************************************************** */
int pd_print_cap_grp(stream, plans, max)
FILE *stream;
PLAN_DATA *plans;
int max;
{
static int error;
static int total;
static int i;
static int j;
static CAP_GRP cg;
error = NO_ERROR;
total = plans->ptr_cap_grp + 1;
max = max < total ? max : total;
printf("%d out of %d ...\n", max, total);
for(i = 0; i < max; i++){
pd_get_cap_grp(plans, i, &cg);
fprintf(stream, "%d ", cg.id);
fprintf(stream, "%s ", cg.nam);
fprintf(stream, "%s ", cg.dscr);
fprintf(stream, "%d ", cg.usage_ofr);
fprintf(stream, "%d ", cg.util_ftr);
fprintf(stream, "%d ", cg.logical_x);
fprintf(stream, "%d ", cg.logical_y);
fprintf(stream, "%d ", cg.prod_seg_cnt);
fprintf(stream, "%d ", cg.resrce_cnt);
fprintf(stream, "%d ", cg.plan_horiz);
fprintf(stream, "%d ", cg.cost_setup);
fprintf(stream, "%d ", cg.cost_run);
fprintf(stream, "%d ", cg.scrap_rate);
fprintf(stream, "%d ", cg.avail);
fprintf(stream, "( ");
for(j = 0; j < cg.prod_seg_cnt; j++){
fprintf(stream, "%d ", cg.prod_seg[j]);
}
fprintf(stream, ") ");
fprintf(stream, "( ");
for(j = 0; j < cg.resrce_cnt; j++){
fprintf(stream, "%d ", cg.resrce_prt[j]);
}
fprintf(stream, ") ");
fprintf(stream, "\n");
}
return error;
}
int pd_print_resrce(stream, plans, max)
FILE *stream;
PLAN_DATA *plans;
int max;
{
static int error;
static int total;
static int i;
static int j;
static RESRCE rs;
error = NO_ERROR;
total = plans->ptr_resrce + 1;
max = max < total ? max : total;
printf("%d out of %d ...\n", max, total);
for(i = 0; i < max; i++){
pd_get_resrce(plans, i, &rs);
fprintf(stream, "%d ", rs.id);
fprintf(stream, "%s ", rs.nam);
fprintf(stream, "%s ", rs.dscr);
fprintf(stream, "%d ", rs.class);
fprintf(stream, "%d ", rs.capab);
fprintf(stream, "%d ", rs.skill);
fprintf(stream, "%d ", rs.qualf);
fprintf(stream, "%d ", rs.quant);
fprintf(stream, "%d ", rs.cost_setup);
fprintf(stream, "%d ", rs.cost_run);
fprintf(stream, "%d ", rs.cost_rate);
fprintf(stream, "%d ", rs.setup_time);
fprintf(stream, "%d ", rs.usage_time);
fprintf(stream, "%d ", rs.avail);
fprintf(stream, "\n");
}
return error;
}
int pd_print_resrce_rel(stream, plans, max)
FILE *stream;
PLAN_DATA *plans;
int max;
{
static int error;
static int total;
static int i;
static int j;
static RESRCE_REL rr;
error = NO_ERROR;
total = plans->ptr_resrce_rel + 1;
max = max < total ? max : total;
printf("%d out of %d ...\n", max, total);
for(i = 0; i < max; i++){
pd_get_resrce_rel(plans, i, &rr);
fprintf(stream, "%d ", rr.id);
fprintf(stream, "%d ", rr.cnst_cnt);
fprintf(stream, "( ");
for(j = 0; j < rr.cnst_cnt; j++){
fprintf(stream, "%d ", rr.cnst[j]);
}
fprintf(stream, ") ");
fprintf(stream, "\n");
}
return error;
}
int pd_print_prt_dat(stream, plans, max)
FILE *stream;
PLAN_DATA *plans;
int max;
{
static int error;
static int total;
static int i;
static int j;
static PRT_DAT pd;
error = NO_ERROR;
total = plans->ptr_prt_dat + 1;
max = max < total ? max : total;
printf("%d out of %d ...\n", max, total);
for(i=0; i < max; i++){
pd_get_prt_dat(plans, i, &pd);
fprintf(stream, "%d ", pd.id);
fprintf(stream, "%s ", pd.nam);
fprintf(stream, "%s ", pd.dscr);
fprintf(stream, "%d ", pd.factory);
fprintf(stream, "%d ", pd.db_key);
fprintf(stream, "%d ", pd.modf_idx);
fprintf(stream, "%d ", pd.unit_m);
fprintf(stream, "%d ", pd.s_t_stat);
fprintf(stream, "\n");
}
return error;
}
int pd_print_prt_cntn(stream, plans, max)
FILE *stream;
PLAN_DATA *plans;
int max;
{
static int error;
static int total;
static int i;
static int j;
static PRT_CNTN pc;
error = NO_ERROR;
total = plans->ptr_prt_cntn + 1;
max = max < total ? max : total;
printf("%d out of %d ...\n", max, total);
for(i=0; i < max; i++){
pd_get_prt_cntn(plans, i, &pc);
fprintf(stream, "%d ", pc.id);
fprintf(stream, "%d ", pc.part_id);
fprintf(stream, "%d ", pc.s_t_consumer);
fprintf(stream, "%d ", pc.s_t_supplier);
fprintf(stream, "%d ", pc.consumer_num);
fprintf(stream, "%d ", pc.relat_fct);
fprintf(stream, "\n");
}
return error;
}
int pd_print_proc_dscr(stream, plans, max)
FILE *stream;
PLAN_DATA *plans;
int max;
{
static int error;
static int total;
static int i;
static int j;
static PROC_DSCR pd;
error = NO_ERROR;
total = plans->ptr_proc_dscr + 1;
max = max < total ? max : total;
printf("%d out of %d ...\n", max, total);
for(i = 0; i < max; i++){
pd_get_proc_dscr(plans, i, &pd);
fprintf(stream, "%d ", pd.id);
fprintf(stream, "%d ", pd.id_s_t);
fprintf(stream, "%d ", pd.id_assoc);
fprintf(stream, "%s ", pd.dscr);
fprintf(stream, "%d ", pd.cap_grp);
fprintf(stream, "%d ", pd.res_cnt);
fprintf(stream, "%d ", pd.est_time_run);
fprintf(stream, "%d ", pd.est_time_setup);
fprintf(stream, "%d ", pd.rank);
fprintf(stream, "%d ", pd.usage_capacity);
fprintf(stream, "%d ", pd.req_capacity);
fprintf(stream, "( ");
for(j = 0; j < pd.res_cnt; j++){
fprintf(stream, "%d ", pd.resrce[j]);
}
fprintf(stream, ") ");
fprintf(stream, "\n");
}
return error;
}
int pd_print_super_task(stream, plans, max)
FILE *stream;
PLAN_DATA *plans;
int max;
{
static int error;
static int total;
static int i;
static int j;
static SUPER_TASK st;
error = NO_ERROR;
total = plans->ptr_super_task + 1;
max = max < total ? max : total;
printf("%d out of %d ...\n", max, total);
for(i=0; i < max; i++){
pd_get_super_task(plans, i, &st);
fprintf(stream, "%d ", st.id);
fprintf(stream, "%s ", st.dscr);
fprintf(stream, "%d ", st.plan_level);
fprintf(stream, "%d ", st.lot_min);
fprintf(stream, "%d ", st.lot_siz);
fprintf(stream, "%d ", st.avg_stock);
fprintf(stream, "%d ", st.scrap_rate);
fprintf(stream, "\n");
}
return error;
}
int pd_print_proc_cntn(stream, plans, max)
FILE *stream;
PLAN_DATA *plans;
int max;
{
static int error;
static int total;
static int i;
static int j;
static PROC_CNTN pc;
error = NO_ERROR;
total = plans->ptr_proc_cntn + 1;
max = max < total ? max : total;
printf("%d out of %d ...\n", max, total);
for(i=0; i < max; i++){
pd_get_proc_cntn(plans, i, &pc);
fprintf(stream, "%d ", pc.id);
fprintf(stream, "%d ", pc.s_t_consumer);
fprintf(stream, "%d ", pc.s_t_supplier);
fprintf(stream, "%d ", pc.min_lead_time);
fprintf(stream, "%d ", pc.relat_quant);
fprintf(stream, "\n");
}
return error;
}
/* ********************************************************
writing PDL file
******************************************************** */
int fi_write_pdl(filename, plans)
char *filename;
PLAN_DATA *plans;
{
static int error;
error = NO_ERROR;
write_data(filename, plans);
return error;
}
/* ********************************************************
reading PDL file
******************************************************** */
int fi_read_pdl(filename, plans)
char *filename;
PLAN_DATA *plans;
{
static int error;
static char progname[10];
error = NO_ERROR;
strcpy(progname, "data");
read_data(progname, filename, plans);
return error;
}
/* ********************************************************
connecting ORACLE database
******************************************************** */
int db_connect()
{
strcpy(uid.arr,"jimmy");
strcpy(pwd.arr,"jimmy");
uid.len=strlen(uid.arr);
pwd.len=strlen(pwd.arr);
printf("Trying to connect to jimmy/jimmy ...");
EXEC SQL WHENEVER SQLERROR GOTO errconnect;
EXEC SQL CONNECT :uid IDENTIFIED BY :pwd;
return(NO_ERROR);
errconnect:
return(ERROR);
}
int db_release()
{
printf("Trying to release from ORACLE ...");
EXEC SQL WHENEVER SQLERROR GOTO errrelease;
EXEC SQL COMMIT WORK RELEASE;
return(NO_ERROR);
errrelease:
return(ERROR);
}
/* ********************************************************
creating database tables
******************************************************** */
int db_creat()
{
if((db_creat_cap_grp() == NO_ERROR) &&
(db_creat_resrce() == NO_ERROR) &&
(db_creat_resrce_rel() == NO_ERROR) &&
(db_creat_prt_dat() == NO_ERROR) &&
(db_creat_prt_cntn() == NO_ERROR) &&
(db_creat_proc_dscr() == NO_ERROR) &&
(db_creat_super_task() == NO_ERROR) &&
(db_creat_proc_cntn() == NO_ERROR)) {
printf("Database action commited ...");
EXEC SQL WHENEVER SQLERROR GOTO err_creat;
EXEC SQL COMMIT;
return(NO_ERROR);
}
err_creat:
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL ROLLBACK;
return(ERROR);
}
int db_creat_cap_grp()
{
printf("Deleting table CAP_GRP ...");
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL DROP TABLE CAP_GRP;
printf("Creating table CAP_GRP ...");
EXEC SQL WHENEVER SQLERROR GOTO err_creat;
EXEC SQL CREATE TABLE CAP_GRP(
ID NUMBER(6) ,
NAM CHAR(30) ,
DSCR CHAR(100) ,
USAGE_OFR NUMBER(3) ,
UTIL_FTR NUMBER(3) ,
LOGICAL_X NUMBER(3) ,
LOGICAL_Y NUMBER(3) ,
PROD_SEG_01 NUMBER(3) ,
PROD_SEG_02 NUMBER(3) ,
PROD_SEG_03 NUMBER(3) ,
PROD_SEG_04 NUMBER(3) ,
PROD_SEG_05 NUMBER(3) ,
PROD_SEG_06 NUMBER(3) ,
PROD_SEG_07 NUMBER(3) ,
PROD_SEG_08 NUMBER(3) ,
PROD_SEG_09 NUMBER(3) ,
PROD_SEG_10 NUMBER(3) ,
PROD_SEG_11 NUMBER(3) ,
PROD_SEG_12 NUMBER(3) ,
PROD_SEG_13 NUMBER(3) ,
PROD_SEG_14 NUMBER(3) ,
PROD_SEG_15 NUMBER(3) ,
PROD_SEG_16 NUMBER(3) ,
PROD_SEG_17 NUMBER(3) ,
PROD_SEG_18 NUMBER(3) ,
PROD_SEG_19 NUMBER(3) ,
PROD_SEG_20 NUMBER(3) ,
PROD_SEG_21 NUMBER(3) ,
PROD_SEG_22 NUMBER(3) ,
PROD_SEG_23 NUMBER(3) ,
PROD_SEG_24 NUMBER(3) ,
PROD_SEG_25 NUMBER(3) ,
PROD_SEG_CNT NUMBER(3) ,
RESRCE_PRT_01 NUMBER(3) ,
RESRCE_PRT_02 NUMBER(3) ,
RESRCE_PRT_03 NUMBER(3) ,
RESRCE_PRT_04 NUMBER(3) ,
RESRCE_PRT_05 NUMBER(3) ,
RESRCE_PRT_06 NUMBER(3) ,
RESRCE_PRT_07 NUMBER(3) ,
RESRCE_PRT_08 NUMBER(3) ,
RESRCE_PRT_09 NUMBER(3) ,
RESRCE_PRT_10 NUMBER(3) ,
RESRCE_PRT_11 NUMBER(3) ,
RESRCE_PRT_12 NUMBER(3) ,
RESRCE_PRT_13 NUMBER(3) ,
RESRCE_PRT_14 NUMBER(3) ,
RESRCE_PRT_15 NUMBER(3) ,
RESRCE_PRT_16 NUMBER(3) ,
RESRCE_PRT_17 NUMBER(3) ,
RESRCE_PRT_18 NUMBER(3) ,
RESRCE_PRT_19 NUMBER(3) ,
RESRCE_PRT_20 NUMBER(3) ,
RESRCE_PRT_21 NUMBER(3) ,
RESRCE_PRT_22 NUMBER(3) ,
RESRCE_PRT_23 NUMBER(3) ,
RESRCE_PRT_24 NUMBER(3) ,
RESRCE_PRT_25 NUMBER(3) ,
RESRCE_CNT NUMBER(3) ,
PLAN_HORIZ NUMBER(6) ,
COST_SETUP NUMBER(6) ,
COST_RUN NUMBER(6) ,
SCRAP_RATE NUMBER(6) ,
AVAIL NUMBER(4) );
printf(" successful\n");
return(NO_ERROR);
err_creat:
return(ERROR);
}
int db_creat_resrce()
{
printf("Deleting table RESRCE ...");
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL DROP TABLE RESRCE;
printf("Creating table RESRCE ...");
EXEC SQL WHENEVER SQLERROR GOTO err_creat;
EXEC SQL CREATE TABLE RESRCE(
ID NUMBER(6) ,
NAM CHAR(30) ,
DSCR CHAR(100) ,
CLASS NUMBER(6) ,
CAPAB NUMBER(6) ,
SKILL NUMBER(6) ,
QUALF NUMBER(6) ,
QUANT NUMBER(6) ,
COST_SETUP NUMBER(6) ,
COST_RUN NUMBER(6) ,
COST_RATE NUMBER(6) ,
SETUP_TIME NUMBER(6) ,
USAGE_TIME NUMBER(6) ,
AVAIL NUMBER(6) );
printf(" successful\n");
return(NO_ERROR);
err_creat:
return(ERROR);
}
int db_creat_resrce_rel()
{
printf("Deleting table RESRCE_REL ...");
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL DROP TABLE RESRCE_REL;
printf("Creating table RESRCE_REL ...");
EXEC SQL WHENEVER SQLERROR GOTO err_creat;
EXEC SQL CREATE TABLE RESRCE_REL(
ID NUMBER(6) ,
CNST_01 NUMBER(3) ,
CNST_02 NUMBER(3) ,
CNST_03 NUMBER(3) ,
CNST_04 NUMBER(3) ,
CNST_05 NUMBER(3) ,
CNST_06 NUMBER(3) ,
CNST_07 NUMBER(3) ,
CNST_08 NUMBER(3) ,
CNST_09 NUMBER(3) ,
CNST_10 NUMBER(3) ,
CNST_CNT NUMBER(3) );
printf(" successful\n");
return(NO_ERROR);
err_creat:
return(ERROR);
}
int db_creat_prt_dat()
{
printf("Deleting table PRT_DAT ...");
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL DROP TABLE PRT_DAT;
printf("Creating table PRT_DAT ...");
EXEC SQL WHENEVER SQLERROR GOTO err_creat;
EXEC SQL CREATE TABLE PRT_DAT(
ID NUMBER(6) ,
NAM CHAR(30) ,
DSCR CHAR(100) ,
FACTORY NUMBER(6) ,
DB_KEY NUMBER(6) ,
MODF_IDX NUMBER(6) ,
UNIT_M NUMBER(6) ,
S_T_STAT NUMBER(6) );
printf(" successful\n");
return(NO_ERROR);
err_creat:
return(ERROR);
}
int db_creat_prt_cntn()
{
printf("Deleting table PRT_CNTN ...");
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL DROP TABLE PRT_CNTN;
printf("Creating table PRT_CNTN ...");
EXEC SQL WHENEVER SQLERROR GOTO err_creat;
EXEC SQL CREATE TABLE PRT_CNTN(
ID NUMBER(6) ,
PART_ID NUMBER(6) ,
S_T_CONSUMER NUMBER(6) ,
S_T_SUPPLIER NUMBER(6) ,
CONSUMER_NUM NUMBER(6) ,
RELAT_FCT NUMBER(6) );
printf(" successful\n");
return(NO_ERROR);
err_creat:
return(ERROR);
}
int db_creat_proc_dscr()
{
printf("Deleting table PROC_DSCR ...");
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL DROP TABLE PROC_DSCR;
printf("Creating table PROC_DSCR ...");
EXEC SQL WHENEVER SQLERROR GOTO err_creat;
EXEC SQL CREATE TABLE PROC_DSCR(
ID NUMBER(6) ,
ID_S_T NUMBER(6) ,
ID_ASSOC NUMBER(6) ,
DSCR CHAR(100) ,
CAP_GRP NUMBER(6) ,
RESRCE_01 NUMBER(3) ,
RESRCE_02 NUMBER(3) ,
RESRCE_03 NUMBER(3) ,
RESRCE_04 NUMBER(3) ,
RESRCE_05 NUMBER(3) ,
RESRCE_06 NUMBER(3) ,
RESRCE_07 NUMBER(3) ,
RESRCE_08 NUMBER(3) ,
RESRCE_09 NUMBER(3) ,
RESRCE_10 NUMBER(3) ,
RES_CNT NUMBER(3) ,
EST_TIME_RUN NUMBER(3) ,
EST_TIME_SETUP NUMBER(3) ,
RANK NUMBER(3) ,
USAGE_CAPACITY NUMBER(6) ,
REQ_CAPACITY NUMBER(6) );
printf(" successful\n");
return(NO_ERROR);
err_creat:
return(ERROR);
}
int db_creat_super_task()
{
printf("Deleting table SUPER_TASK ...");
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL DROP TABLE SUPER_TASK;
printf("Creating table SUPER_TASK ...");
EXEC SQL WHENEVER SQLERROR GOTO err_creat;
EXEC SQL CREATE TABLE SUPER_TASK(
ID NUMBER(6) ,
DSCR CHAR(100) ,
PLAN_LEVEL NUMBER(6) ,
LOT_MIN NUMBER(6) ,
LOT_SIZ NUMBER(6) ,
AVG_STOCK NUMBER(6) ,
SCRAP_RATE NUMBER(6) );
printf(" successful\n");
return(NO_ERROR);
err_creat:
return(ERROR);
}
int db_creat_proc_cntn()
{
printf("Deleting table PROC_CNTN ...");
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL DROP TABLE PROC_CNTN;
printf("Creating table PROC_CNTN ...");
EXEC SQL WHENEVER SQLERROR GOTO err_creat;
EXEC SQL CREATE TABLE PROC_CNTN(
ID NUMBER(6) ,
S_T_CONSUMER NUMBER(6) ,
S_T_SUPPLIER NUMBER(6) ,
MIN_LEAD_TIME NUMBER(6) ,
RELAT_QUANT NUMBER(6) );
printf(" successful\n");
return(NO_ERROR);
err_creat:
return(ERROR);
}
/* ********************************************************
writing database tables
******************************************************** */
int db_write(plans)
PLAN_DATA *plans;
{
if((db_write_cap_grp(plans) == NO_ERROR) &&
(db_write_resrce(plans) == NO_ERROR) &&
(db_write_resrce_rel(plans) == NO_ERROR) &&
(db_write_prt_dat(plans) == NO_ERROR) &&
(db_write_prt_cntn(plans) == NO_ERROR) &&
(db_write_proc_dscr(plans) == NO_ERROR) &&
(db_write_super_task(plans) == NO_ERROR) &&
(db_write_proc_cntn(plans) == NO_ERROR)) {
printf("Database action commited ...");
EXEC SQL WHENEVER SQLERROR GOTO err_write;
EXEC SQL COMMIT;
return(NO_ERROR);
}
err_write:
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL ROLLBACK;
return(ERROR);
}
int db_write_cap_grp(plans)
PLAN_DATA *plans;
{
int i;
int j;
printf("Inserting into table cap_grp ...");
EXEC SQL WHENEVER SQLERROR GOTO err_write;
for(i = 0; i <= plans->ptr_cap_grp; i++){
printf(" %d",i);
id = plans->cap_grp[i].id; /* id */
for(j = 0; plans->cap_grp[i].nam[j] != 0; j++){
nam.arr[j] = plans->cap_grp[i].nam[j];
}
nam.arr[j] = 0; /* nam */
nam.len = j;
for(j = 0; plans->cap_grp[i].dscr[j] != 0; j++){
dscr.arr[j] = plans->cap_grp[i].dscr[j];
}
dscr.arr[j] = 0; /* dscr */
dscr.len = j;
usage_ofr = plans->cap_grp[i].usage_ofr; /* usage_ofr */
util_ftr = plans->cap_grp[i].util_ftr; /* util_Ftr */
logical_x = plans->cap_grp[i].logical_x; /* logical_x */
logical_y = plans->cap_grp[i].logical_y; /* logical_y */
/* prod_seg */
prod_seg_01 = 0 <= plans->cap_grp[i].prod_seg_cnt
? plans->cap_grp[i].prod_seg[0] : 0;
prod_seg_02 = 1 <= plans->cap_grp[i].prod_seg_cnt
? plans->cap_grp[i].prod_seg[1] : 0;
prod_seg_03 = 2 <= plans->cap_grp[i].prod_seg_cnt
? plans->cap_grp[i].prod_seg[2] : 0;
prod_seg_04 = 3 <= plans->cap_grp[i].prod_seg_cnt
? plans->cap_grp[i].prod_seg[3] : 0;
prod_seg_05 = 4 <= plans->cap_grp[i].prod_seg_cnt
? plans->cap_grp[i].prod_seg[4] : 0;
prod_seg_06 = 5 <= plans->cap_grp[i].prod_seg_cnt
? plans->cap_grp[i].prod_seg[5] : 0;
prod_seg_07 = 6 <= plans->cap_grp[i].prod_seg_cnt
? plans->cap_grp[i].prod_seg[6] : 0;
prod_seg_08 = 7 <= plans->cap_grp[i].prod_seg_cnt
? plans->cap_grp[i].prod_seg[7] : 0;
prod_seg_09 = 8 <= plans->cap_grp[i].prod_seg_cnt
? plans->cap_grp[i].prod_seg[8] : 0;
prod_seg_10 = 9 <= plans->cap_grp[i].prod_seg_cnt
? plans->cap_grp[i].prod_seg[9] : 0;
prod_seg_11 = 10 <= plans->cap_grp[i].prod_seg_cnt
? plans->cap_grp[i].prod_seg[10] : 0;
prod_seg_12 = 11 <= plans->cap_grp[i].prod_seg_cnt
? plans->cap_grp[i].prod_seg[11] : 0;
prod_seg_13 = 12 <= plans->cap_grp[i].prod_seg_cnt
? plans->cap_grp[i].prod_seg[12] : 0;
prod_seg_14 = 13 <= plans->cap_grp[i].prod_seg_cnt
? plans->cap_grp[i].prod_seg[13] : 0;
prod_seg_15 = 14 <= plans->cap_grp[i].prod_seg_cnt
? plans->cap_grp[i].prod_seg[14] : 0;
prod_seg_16 = 15 <= plans->cap_grp[i].prod_seg_cnt
? plans->cap_grp[i].prod_seg[15] : 0;
prod_seg_17 = 16 <= plans->cap_grp[i].prod_seg_cnt
? plans->cap_grp[i].prod_seg[16] : 0;
prod_seg_18 = 17 <= plans->cap_grp[i].prod_seg_cnt
? plans->cap_grp[i].prod_seg[17] : 0;
prod_seg_19 = 18 <= plans->cap_grp[i].prod_seg_cnt
? plans->cap_grp[i].prod_seg[18] : 0;
prod_seg_20 = 19 <= plans->cap_grp[i].prod_seg_cnt
? plans->cap_grp[i].prod_seg[19] : 0;
prod_seg_21 = 20 <= plans->cap_grp[i].prod_seg_cnt
? plans->cap_grp[i].prod_seg[20] : 0;
prod_seg_22 = 21 <= plans->cap_grp[i].prod_seg_cnt
? plans->cap_grp[i].prod_seg[21] : 0;
prod_seg_23 = 22 <= plans->cap_grp[i].prod_seg_cnt
? plans->cap_grp[i].prod_seg[22] : 0;
prod_seg_24 = 23 <= plans->cap_grp[i].prod_seg_cnt
? plans->cap_grp[i].prod_seg[23] : 0;
prod_seg_25 = 24 <= plans->cap_grp[i].prod_seg_cnt
? plans->cap_grp[i].prod_seg[24] : 0;
/* prod_seg_cnt */
prod_seg_cnt = plans->cap_grp[i].prod_seg_cnt;
/* resrce_prt */
resrce_prt_01 = 0 <= plans->cap_grp[i].resrce_cnt
? plans->cap_grp[i].resrce_prt[0] : 0;
resrce_prt_02 = 1 <= plans->cap_grp[i].resrce_cnt
? plans->cap_grp[i].resrce_prt[1] : 0;
resrce_prt_03 = 2 <= plans->cap_grp[i].resrce_cnt
? plans->cap_grp[i].resrce_prt[2] : 0;
resrce_prt_04 = 3 <= plans->cap_grp[i].resrce_cnt
? plans->cap_grp[i].resrce_prt[3] : 0;
resrce_prt_05 = 4 <= plans->cap_grp[i].resrce_cnt
? plans->cap_grp[i].resrce_prt[4] : 0;
resrce_prt_06 = 5 <= plans->cap_grp[i].resrce_cnt
? plans->cap_grp[i].resrce_prt[5] : 0;
resrce_prt_07 = 6 <= plans->cap_grp[i].resrce_cnt
? plans->cap_grp[i].resrce_prt[6] : 0;
resrce_prt_08 = 7 <= plans->cap_grp[i].resrce_cnt
? plans->cap_grp[i].resrce_prt[7] : 0;
resrce_prt_09 = 8 <= plans->cap_grp[i].resrce_cnt
? plans->cap_grp[i].resrce_prt[8] : 0;
resrce_prt_10 = 9 <= plans->cap_grp[i].resrce_cnt
? plans->cap_grp[i].resrce_prt[9] : 0;
resrce_prt_11 = 10 <= plans->cap_grp[i].resrce_cnt
? plans->cap_grp[i].resrce_prt[10] : 0;
resrce_prt_12 = 11 <= plans->cap_grp[i].resrce_cnt
? plans->cap_grp[i].resrce_prt[11] : 0;
resrce_prt_13 = 12 <= plans->cap_grp[i].resrce_cnt
? plans->cap_grp[i].resrce_prt[12] : 0;
resrce_prt_14 = 13 <= plans->cap_grp[i].resrce_cnt
? plans->cap_grp[i].resrce_prt[13] : 0;
resrce_prt_15 = 14 <= plans->cap_grp[i].resrce_cnt
? plans->cap_grp[i].resrce_prt[14] : 0;
resrce_prt_16 = 15 <= plans->cap_grp[i].resrce_cnt
? plans->cap_grp[i].resrce_prt[15] : 0;
resrce_prt_17 = 16 <= plans->cap_grp[i].resrce_cnt
? plans->cap_grp[i].resrce_prt[16] : 0;
resrce_prt_18 = 17 <= plans->cap_grp[i].resrce_cnt
? plans->cap_grp[i].resrce_prt[17] : 0;
resrce_prt_19 = 18 <= plans->cap_grp[i].resrce_cnt
? plans->cap_grp[i].resrce_prt[18] : 0;
resrce_prt_20 = 19 <= plans->cap_grp[i].resrce_cnt
? plans->cap_grp[i].resrce_prt[19] : 0;
resrce_prt_21 = 20 <= plans->cap_grp[i].resrce_cnt
? plans->cap_grp[i].resrce_prt[20] : 0;
resrce_prt_22 = 21 <= plans->cap_grp[i].resrce_cnt
? plans->cap_grp[i].resrce_prt[21] : 0;
resrce_prt_23 = 22 <= plans->cap_grp[i].resrce_cnt
? plans->cap_grp[i].resrce_prt[22] : 0;
resrce_prt_24 = 23 <= plans->cap_grp[i].resrce_cnt
? plans->cap_grp[i].resrce_prt[23] : 0;
resrce_prt_25 = 24 <= plans->cap_grp[i].resrce_cnt
? plans->cap_grp[i].resrce_prt[24] : 0;
resrce_cnt = plans->cap_grp[i].resrce_cnt; /* resrce_cnt */
plan_horiz = plans->cap_grp[i].plan_horiz; /* plan_horiz */
cost_setup = plans->cap_grp[i].cost_setup; /* cost_setup */
cost_run = plans->cap_grp[i].cost_run; /* cost_run */
scrap_rate = plans->cap_grp[i].scrap_rate; /* scrap_rate */
avail = plans->cap_grp[i].avail; /* avail */
EXEC SQL INSERT INTO CAP_GRP
(
ID,NAM,DSCR,USAGE_OFR,UTIL_FTR,LOGICAL_X,LOGICAL_Y,
PROD_SEG_01,PROD_SEG_02,PROD_SEG_03,PROD_SEG_04,
PROD_SEG_05,PROD_SEG_06,PROD_SEG_07,PROD_SEG_08,
PROD_SEG_09,PROD_SEG_10,PROD_SEG_11,PROD_SEG_12,
PROD_SEG_13,PROD_SEG_14,PROD_SEG_15,PROD_SEG_16,
PROD_SEG_17,PROD_SEG_18,PROD_SEG_19,PROD_SEG_20,
PROD_SEG_21,PROD_SEG_22,PROD_SEG_23,PROD_SEG_24,
PROD_SEG_25,PROD_SEG_CNT,
RESRCE_PRT_01,RESRCE_PRT_02,RESRCE_PRT_03,RESRCE_PRT_04,
RESRCE_PRT_05,RESRCE_PRT_06,RESRCE_PRT_07,RESRCE_PRT_08,
RESRCE_PRT_09,RESRCE_PRT_10,RESRCE_PRT_11,RESRCE_PRT_12,
RESRCE_PRT_13,RESRCE_PRT_14,RESRCE_PRT_15,RESRCE_PRT_16,
RESRCE_PRT_17,RESRCE_PRT_18,RESRCE_PRT_19,RESRCE_PRT_20,
RESRCE_PRT_21,RESRCE_PRT_22,RESRCE_PRT_23,RESRCE_PRT_24,
RESRCE_PRT_25,RESRCE_CNT,
PLAN_HORIZ,COST_SETUP,COST_RUN,SCRAP_RATE,AVAIL
)
VALUES
(
:id,:nam,:dscr,:usage_ofr,:util_ftr,:logical_x,:logical_y,
:prod_seg_01,:prod_seg_02,:prod_seg_03,:prod_seg_04,
:prod_seg_05,:prod_seg_06,:prod_seg_07,:prod_seg_08,
:prod_seg_09,:prod_seg_10,:prod_seg_11,:prod_seg_12,
:prod_seg_13,:prod_seg_14,:prod_seg_15,:prod_seg_16,
:prod_seg_17,:prod_seg_18,:prod_seg_19,:prod_seg_20,
:prod_seg_21,:prod_seg_22,:prod_seg_23,:prod_seg_24,
:prod_seg_25,:prod_seg_cnt,
:resrce_prt_01,:resrce_prt_02,:resrce_prt_03,:resrce_prt_04,
:resrce_prt_05,:resrce_prt_06,:resrce_prt_07,:resrce_prt_08,
:resrce_prt_09,:resrce_prt_10,:resrce_prt_11,:resrce_prt_12,
:resrce_prt_13,:resrce_prt_14,:resrce_prt_15,:resrce_prt_16,
:resrce_prt_17,:resrce_prt_18,:resrce_prt_19,:resrce_prt_20,
:resrce_prt_21,:resrce_prt_22,:resrce_prt_23,:resrce_prt_24,
:resrce_prt_25,:resrce_cnt,
:plan_horiz,:cost_setup,:cost_run,:scrap_rate,:avail
);
}
printf(" successful\n");
return(NO_ERROR);
err_write:
return(ERROR);
}
int db_write_resrce(plans)
PLAN_DATA *plans;
{
int i;
int j;
printf("Inserting into table resrce ...");
EXEC SQL WHENEVER SQLERROR GOTO err_write;
for(i = 0; i <= plans->ptr_resrce; i++){
printf(" %d",i);
id = plans->resrce[i].id; /* id */
for(j = 0; plans->resrce[i].nam[j] != 0; j++){
nam.arr[j] = plans->resrce[i].nam[j];
}
nam.arr[j] = 0; /* nam */
nam.len = j;
for(j = 0; plans->resrce[i].dscr[j] != 0; j++){
dscr.arr[j] = plans->resrce[i].dscr[j];
}
dscr.arr[j] = 0; /* dscr */
dscr.len = j;
class = plans->resrce[i].class; /* class */
capab = plans->resrce[i].capab; /* capab */
skill = plans->resrce[i].skill; /* skill */
qualf = plans->resrce[i].qualf; /* qualf */
quant = plans->resrce[i].quant; /* quant */
cost_setup = plans->resrce[i].cost_setup; /* cost_setup */
cost_run = plans->resrce[i].cost_run; /* cost_run */
cost_rate = plans->resrce[i].cost_rate; /* cost_rate */
setup_time = plans->resrce[i].setup_time; /* setup_time */
usage_time = plans->resrce[i].usage_time; /* usage_time */
avail = plans->resrce[i].avail; /* avail */
EXEC SQL INSERT INTO RESRCE
(
ID,NAM,DSCR,
CLASS,CAPAB,SKILL,QUALF,QUANT,
COST_SETUP,COST_RUN,COST_RATE,
SETUP_TIME,USAGE_TIME,AVAIL
)
VALUES
(
:id,:nam,:dscr,
:class,:capab,:skill,:qualf,:quant,
:cost_setup,:cost_run,:cost_rate,
:setup_time,:usage_time,:avail
);
}
printf(" successful\n");
return(NO_ERROR);
err_write:
return(ERROR);
}
int db_write_resrce_rel(plans)
PLAN_DATA *plans;
{
int i;
int j;
printf("Inserting into table resrce_rel ...");
EXEC SQL WHENEVER SQLERROR GOTO err_write;
for(i = 0; i <= plans->ptr_resrce_rel; i++){
printf(" %d",i);
id = plans->resrce_rel[i].id; /* id */
/* cnst */
cnst_01 = 0 <= plans->resrce_rel[i].cnst_cnt
? plans->resrce_rel[i].cnst[0] : 0;
cnst_02 = 1 <= plans->resrce_rel[i].cnst_cnt
? plans->resrce_rel[i].cnst[1] : 0;
cnst_03 = 2 <= plans->resrce_rel[i].cnst_cnt
? plans->resrce_rel[i].cnst[2] : 0;
cnst_04 = 3 <= plans->resrce_rel[i].cnst_cnt
? plans->resrce_rel[i].cnst[3] : 0;
cnst_05 = 4 <= plans->resrce_rel[i].cnst_cnt
? plans->resrce_rel[i].cnst[4] : 0;
cnst_06 = 5 <= plans->resrce_rel[i].cnst_cnt
? plans->resrce_rel[i].cnst[5] : 0;
cnst_07 = 6 <= plans->resrce_rel[i].cnst_cnt
? plans->resrce_rel[i].cnst[6] : 0;
cnst_08 = 7 <= plans->resrce_rel[i].cnst_cnt
? plans->resrce_rel[i].cnst[7] : 0;
cnst_09 = 8 <= plans->resrce_rel[i].cnst_cnt
? plans->resrce_rel[i].cnst[8] : 0;
cnst_10 = 9 <= plans->resrce_rel[i].cnst_cnt
? plans->resrce_rel[i].cnst[9] : 0;
/* cnst_cnt */
cnst_cnt = plans->resrce_rel[i].cnst_cnt;
EXEC SQL INSERT INTO RESRCE_REL
(
ID,
CNST_01,CNST_02,CNST_03,CNST_04,CNST_05,
CNST_06,CNST_07,CNST_08,CNST_09,CNST_10, CNST_CNT
)
VALUES
(
:id,
:cnst_01,:cnst_02,:cnst_03,:cnst_04,:cnst_05,
:cnst_06,:cnst_07,:cnst_08,:cnst_09,:cnst_10,:cnst_cnt
);
}
printf(" successful\n");
return(NO_ERROR);
err_write:
return(ERROR);
}
int db_write_prt_dat(plans)
PLAN_DATA *plans;
{
int i;
int j;
printf("Inserting into table prt_dat ...");
EXEC SQL WHENEVER SQLERROR GOTO err_write;
for(i = 0; i <= plans->ptr_prt_dat; i++){
printf(" %d",i);
id = plans->prt_dat[i].id; /* id */
for(j = 0; plans->prt_dat[i].nam[j] != 0; j++){
nam.arr[j] = plans->prt_dat[i].nam[j];
}
nam.arr[j] = 0; /* nam */
nam.len = j;
for(j = 0; plans->prt_dat[i].dscr[j] != 0; j++){
dscr.arr[j] = plans->prt_dat[i].dscr[j];
}
dscr.arr[j] = 0; /* dscr */
dscr.len = j;
factory = plans->prt_dat[i].factory; /* factory */
db_key = plans->prt_dat[i].db_key; /* db_key */
modf_idx = plans->prt_dat[i].modf_idx; /* modf_idx */
unit_m = plans->prt_dat[i].unit_m; /* unit_m */
s_t_stat = plans->prt_dat[i].s_t_stat; /* s_t_stat */
EXEC SQL INSERT INTO PRT_DAT
(
ID,NAM,DSCR,FACTORY,DB_KEY,MODF_IDX,UNIT_M,S_T_STAT
)
VALUES
(
:id,:nam,:dscr,:factory,:db_key,:modf_idx,:unit_m,:s_t_stat
);
}
printf(" successful\n");
return(NO_ERROR);
err_write:
return(ERROR);
}
int db_write_prt_cntn(plans)
PLAN_DATA *plans;
{
int i;
int j;
printf("Inserting into table prt_cntn ...");
EXEC SQL WHENEVER SQLERROR GOTO err_write;
for(i = 0; i <= plans->ptr_prt_cntn; i++){
printf(" %d",i);
id = plans->prt_cntn[i].id; /* id */
part_id = plans->prt_cntn[i].part_id; /* part_id */
/* s_t_consumer */
s_t_consumer = plans->prt_cntn[i].s_t_consumer;
/* s_t_supplier */
s_t_supplier = plans->prt_cntn[i].s_t_supplier;
/* consumer_num */
consumer_num = plans->prt_cntn[i].consumer_num;
relat_fct = plans->prt_cntn[i].relat_fct; /* relat_fct */
EXEC SQL INSERT INTO PRT_CNTN
(
ID,PART_ID,S_T_CONSUMER,S_T_SUPPLIER,CONSUMER_NUM,RELAT_FCT
)
VALUES
(
:id,:part_id,:s_t_consumer,:s_t_supplier,:consumer_num,:relat_fct
);
}
printf(" successful\n");
return(NO_ERROR);
err_write:
return(ERROR);
}
int db_write_proc_dscr(plans)
PLAN_DATA *plans;
{
int i;
int j;
printf("Inserting into table proc_dscr ...");
EXEC SQL WHENEVER SQLERROR GOTO err_write;
for(i = 0; i <= plans->ptr_proc_dscr; i++){
printf(" %d",i);
id = plans->proc_dscr[i].id; /* id */
id_s_t = plans->proc_dscr[i].id_s_t; /* id_s_t */
id_assoc = plans->proc_dscr[i].id_assoc; /* id_assoc */
for(j = 0; plans->proc_dscr[i].dscr[j] != 0; j++){
dscr.arr[j] = plans->proc_dscr[i].dscr[j];
}
dscr.arr[j] = 0; /* dscr */
dscr.len = j;
cap_grp = plans->proc_dscr[i].cap_grp; /* cap_grp */
/* resrce */
resrce_01 = 0 <= plans->proc_dscr[i].res_cnt
? plans->proc_dscr[i].resrce[0] : 0;
resrce_02 = 1 <= plans->proc_dscr[i].res_cnt
? plans->proc_dscr[i].resrce[1] : 0;
resrce_03 = 2 <= plans->proc_dscr[i].res_cnt
? plans->proc_dscr[i].resrce[2] : 0;
resrce_04 = 3 <= plans->proc_dscr[i].res_cnt
? plans->proc_dscr[i].resrce[3] : 0;
resrce_05 = 4 <= plans->proc_dscr[i].res_cnt
? plans->proc_dscr[i].resrce[4] : 0;
resrce_06 = 5 <= plans->proc_dscr[i].res_cnt
? plans->proc_dscr[i].resrce[5] : 0;
resrce_07 = 6 <= plans->proc_dscr[i].res_cnt
? plans->proc_dscr[i].resrce[6] : 0;
resrce_08 = 7 <= plans->proc_dscr[i].res_cnt
? plans->proc_dscr[i].resrce[7] : 0;
resrce_09 = 8 <= plans->proc_dscr[i].res_cnt
? plans->proc_dscr[i].resrce[8] : 0;
resrce_10 = 9 <= plans->proc_dscr[i].res_cnt
? plans->proc_dscr[i].resrce[9] : 0;
res_cnt = plans->proc_dscr[i].res_cnt; /* res_cnt */
/* est_time_run */
est_time_run = plans->proc_dscr[i].est_time_run;
/* est_time_run */
est_time_setup = plans->proc_dscr[i].est_time_setup;
rank = plans->proc_dscr[i].rank; /* est_time_run */
/* usagecapacity*/
usage_capacity = plans->proc_dscr[i].usage_capacity;
/* req_capacity */
req_capacity = plans->proc_dscr[i].req_capacity;
EXEC SQL INSERT INTO PROC_DSCR
(
ID,ID_S_T,ID_ASSOC,DSCR,CAP_GRP,
RESRCE_01,RESRCE_02,RESRCE_03,RESRCE_04,RESRCE_05,
RESRCE_06,RESRCE_07,RESRCE_08,RESRCE_09,RESRCE_10,
RES_CNT,EST_TIME_RUN,EST_TIME_SETUP,
RANK,USAGE_CAPACITY,REQ_CAPACITY
)
VALUES
(
:id,:id_s_t,:id_assoc,:dscr,:cap_grp,
:resrce_01,:resrce_02,:resrce_03,:resrce_04,:resrce_05,
:resrce_06,:resrce_07,:resrce_08,:resrce_09,:resrce_10,
:res_cnt,:est_time_run,:est_time_setup,
:rank,:usage_capacity,:req_capacity
);
}
printf(" successful\n");
return(NO_ERROR);
err_write:
return(ERROR);
}
int db_write_super_task(plans)
PLAN_DATA *plans;
{
int i;
int j;
printf("Inserting into table super_task ...");
EXEC SQL WHENEVER SQLERROR GOTO err_write;
for(i = 0; i <= plans->ptr_super_task; i++){
printf(" %d",i);
id = plans->super_task[i].id; /* id */
for(j = 0; plans->super_task[i].dscr[j] != 0; j++){
dscr.arr[j] = plans->super_task[i].dscr[j];
}
dscr.arr[j] = 0; /* dscr */
dscr.len = j;
/* plan_level */
plan_level = plans->super_task[i].plan_level;
lot_min = plans->super_task[i].lot_min; /* lot_min */
lot_siz = plans->super_task[i].lot_siz; /* lot_siz */
/* avg_stock */
avg_stock = plans->super_task[i].avg_stock;
/* scrap_rate */
scrap_rate = plans->super_task[i].scrap_rate;
EXEC SQL INSERT INTO SUPER_TASK
(
ID,DSCR,PLAN_LEVEL,LOT_MIN,LOT_SIZ,AVG_STOCK,SCRAP_RATE
)
VALUES
(
:id,:dscr,:plan_level,:lot_min,:lot_siz,:avg_stock,:scrap_rate
);
}
printf(" successful\n");
return(NO_ERROR);
err_write:
return(ERROR);
}
int db_write_proc_cntn(plans)
PLAN_DATA *plans;
{
int i;
int j;
printf("Inserting into table proc_cntn ...");
EXEC SQL WHENEVER SQLERROR GOTO err_write;
for(i = 0; i <= plans->ptr_proc_cntn; i++){
printf(" %d",i);
id = plans->proc_cntn[i].id; /* id */
/* s_t_consumer */
s_t_consumer = plans->proc_cntn[i].s_t_consumer;
/* s_t_supplier */
s_t_supplier = plans->proc_cntn[i].s_t_supplier;
/* min_lead_time*/
min_lead_time = plans->proc_cntn[i].min_lead_time;
/* relat_quant */
relat_quant = plans->proc_cntn[i].relat_quant;
EXEC SQL INSERT INTO PROC_CNTN
(
ID,S_T_CONSUMER,S_T_SUPPLIER,MIN_LEAD_TIME,RELAT_QUANT
)
VALUES
(
:id,:s_t_consumer,:s_t_supplier,:min_lead_time,:relat_quant
);
}
printf(" successful\n");
return(NO_ERROR);
err_write:
return(ERROR);
}
/* ********************************************************
reading database tables
******************************************************** */
int db_read(plans)
PLAN_DATA *plans;
{
int p_cap_grp;
int p_resrce;
int p_resrce_rel;
int p_prt_dat;
int p_prt_cntn;
int p_proc_dscr;
int p_super_task;
int p_proc_cntn;
p_cap_grp = plans->ptr_cap_grp;
p_resrce = plans->ptr_resrce;
p_resrce_rel = plans->ptr_resrce_rel;
p_prt_dat = plans->ptr_prt_dat;
p_prt_cntn = plans->ptr_prt_cntn;
p_proc_dscr = plans->ptr_proc_dscr;
p_super_task = plans->ptr_super_task;
p_proc_cntn = plans->ptr_proc_cntn;
if((db_read_cap_grp(plans) == NO_ERROR) &&
(db_read_resrce(plans) == NO_ERROR) &&
(db_read_resrce_rel(plans) == NO_ERROR) &&
(db_read_prt_dat(plans) == NO_ERROR) &&
(db_read_prt_cntn(plans) == NO_ERROR) &&
(db_read_proc_dscr(plans) == NO_ERROR) &&
(db_read_super_task(plans) == NO_ERROR) &&
(db_read_proc_cntn(plans) == NO_ERROR)) {
printf("Database action ...");
return(NO_ERROR);
}else{
plans->ptr_cap_grp = p_cap_grp;
plans->ptr_resrce = p_resrce;
plans->ptr_resrce_rel = p_resrce_rel;
plans->ptr_prt_dat = p_prt_dat;
plans->ptr_prt_cntn = p_prt_cntn;
plans->ptr_proc_dscr = p_proc_dscr;
plans->ptr_super_task = p_super_task;
plans->ptr_proc_cntn = p_proc_cntn;
return(ERROR);
}
}
int db_read_cap_grp(plans)
PLAN_DATA *plans;
{
int i;
int j;
int k;
printf("Extracting from table cap_grp ...");
EXEC SQL WHENEVER SQLERROR GOTO err_read;
EXEC SQL DECLARE C1 CURSOR FOR
SELECT * FROM CAP_GRP;
EXEC SQL OPEN C1;
EXEC SQL WHENEVER NOT FOUND GOTO end_read;
for(i = 0; ; i++){
EXEC SQL FETCH C1 INTO
:id,:nam,:dscr,:usage_ofr,:util_ftr,:logical_x,:logical_y,
:prod_seg_01,:prod_seg_02,:prod_seg_03,:prod_seg_04,
:prod_seg_05,:prod_seg_06,:prod_seg_07,:prod_seg_08,
:prod_seg_09,:prod_seg_10,:prod_seg_11,:prod_seg_12,
:prod_seg_13,:prod_seg_14,:prod_seg_15,:prod_seg_16,
:prod_seg_17,:prod_seg_18,:prod_seg_19,:prod_seg_20,
:prod_seg_21,:prod_seg_22,:prod_seg_23,:prod_seg_24,
:prod_seg_25,:prod_seg_cnt,
:resrce_prt_01,:resrce_prt_02,:resrce_prt_03,:resrce_prt_04,
:resrce_prt_05,:resrce_prt_06,:resrce_prt_07,:resrce_prt_08,
:resrce_prt_09,:resrce_prt_10,:resrce_prt_11,:resrce_prt_12,
:resrce_prt_13,:resrce_prt_14,:resrce_prt_15,:resrce_prt_16,
:resrce_prt_17,:resrce_prt_18,:resrce_prt_19,:resrce_prt_20,
:resrce_prt_21,:resrce_prt_22,:resrce_prt_23,:resrce_prt_24,
:resrce_prt_25,:resrce_cnt,
:plan_horiz,:cost_setup,:cost_run,:scrap_rate,:avail;
printf(" %d", i);
j = ++plans->ptr_cap_grp;
plans->cap_grp[j].id = id;
for (k = 0; k < nam.len; k++) {
plans->cap_grp[j].nam[k] = nam.arr[k];
}
plans->cap_grp[j].nam[k] = 0;
for (k = 0; k < dscr.len; k++) {
plans->cap_grp[j].dscr[k] = dscr.arr[k];
}
plans->cap_grp[j].dscr[k] = 0;
plans->cap_grp[j].usage_ofr = usage_ofr;
plans->cap_grp[j].util_ftr = util_ftr;
plans->cap_grp[j].logical_x = logical_x;
plans->cap_grp[j].logical_y = logical_y;
plans->cap_grp[j].prod_seg[0] = prod_seg_01;
plans->cap_grp[j].prod_seg[1] = prod_seg_02;
plans->cap_grp[j].prod_seg[2] = prod_seg_03;
plans->cap_grp[j].prod_seg[3] = prod_seg_04;
plans->cap_grp[j].prod_seg[4] = prod_seg_05;
plans->cap_grp[j].prod_seg[5] = prod_seg_06;
plans->cap_grp[j].prod_seg[6] = prod_seg_07;
plans->cap_grp[j].prod_seg[7] = prod_seg_08;
plans->cap_grp[j].prod_seg[8] = prod_seg_09;
plans->cap_grp[j].prod_seg[9] = prod_seg_10;
plans->cap_grp[j].prod_seg[10] = prod_seg_11;
plans->cap_grp[j].prod_seg[11] = prod_seg_12;
plans->cap_grp[j].prod_seg[12] = prod_seg_13;
plans->cap_grp[j].prod_seg[13] = prod_seg_14;
plans->cap_grp[j].prod_seg[14] = prod_seg_15;
plans->cap_grp[j].prod_seg[15] = prod_seg_16;
plans->cap_grp[j].prod_seg[16] = prod_seg_17;
plans->cap_grp[j].prod_seg[17] = prod_seg_18;
plans->cap_grp[j].prod_seg[18] = prod_seg_19;
plans->cap_grp[j].prod_seg[19] = prod_seg_20;
plans->cap_grp[j].prod_seg[20] = prod_seg_21;
plans->cap_grp[j].prod_seg[21] = prod_seg_22;
plans->cap_grp[j].prod_seg[22] = prod_seg_23;
plans->cap_grp[j].prod_seg[23] = prod_seg_24;
plans->cap_grp[j].prod_seg[24] = prod_seg_25;
plans->cap_grp[j].prod_seg_cnt = prod_seg_cnt;
plans->cap_grp[j].resrce_prt[0] = resrce_prt_01;
plans->cap_grp[j].resrce_prt[1] = resrce_prt_02;
plans->cap_grp[j].resrce_prt[2] = resrce_prt_03;
plans->cap_grp[j].resrce_prt[3] = resrce_prt_04;
plans->cap_grp[j].resrce_prt[4] = resrce_prt_05;
plans->cap_grp[j].resrce_prt[5] = resrce_prt_06;
plans->cap_grp[j].resrce_prt[6] = resrce_prt_07;
plans->cap_grp[j].resrce_prt[7] = resrce_prt_08;
plans->cap_grp[j].resrce_prt[8] = resrce_prt_09;
plans->cap_grp[j].resrce_prt[9] = resrce_prt_10;
plans->cap_grp[j].resrce_prt[10]= resrce_prt_11;
plans->cap_grp[j].resrce_prt[11]= resrce_prt_12;
plans->cap_grp[j].resrce_prt[12]= resrce_prt_13;
plans->cap_grp[j].resrce_prt[13]= resrce_prt_14;
plans->cap_grp[j].resrce_prt[14]= resrce_prt_15;
plans->cap_grp[j].resrce_prt[15]= resrce_prt_16;
plans->cap_grp[j].resrce_prt[16]= resrce_prt_17;
plans->cap_grp[j].resrce_prt[17]= resrce_prt_18;
plans->cap_grp[j].resrce_prt[18]= resrce_prt_19;
plans->cap_grp[j].resrce_prt[19]= resrce_prt_20;
plans->cap_grp[j].resrce_prt[20]= resrce_prt_21;
plans->cap_grp[j].resrce_prt[21]= resrce_prt_22;
plans->cap_grp[j].resrce_prt[22]= resrce_prt_23;
plans->cap_grp[j].resrce_prt[23]= resrce_prt_24;
plans->cap_grp[j].resrce_prt[24]= resrce_prt_25;
plans->cap_grp[j].resrce_cnt = resrce_cnt;
plans->cap_grp[j].plan_horiz = plan_horiz;
plans->cap_grp[j].cost_setup = cost_setup;
plans->cap_grp[j].cost_run = cost_run;
plans->cap_grp[j].scrap_rate = scrap_rate;
plans->cap_grp[j].avail = avail;
}
end_read:
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL CLOSE C1;
printf(" successful\n");
return(NO_ERROR);
err_read:
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL CLOSE C1;
return(ERROR);
}
int db_read_resrce(plans)
PLAN_DATA *plans;
{
int i;
int j;
int k;
printf("Extracting from table resrce ...");
EXEC SQL WHENEVER SQLERROR GOTO err_read;
EXEC SQL DECLARE C2 CURSOR FOR
SELECT * FROM RESRCE;
EXEC SQL OPEN C2;
EXEC SQL WHENEVER NOT FOUND GOTO end_read;
for(i = 0; ; i++){
EXEC SQL FETCH C2 INTO
:id,:nam,:dscr,
:class,:capab,:skill,:qualf,:quant,
:cost_setup,:cost_run,:cost_rate,
:setup_time,:usage_time,:avail;
printf(" %d", i);
j = ++plans->ptr_resrce;
plans->resrce[j].id = id;
for (k = 0; k < nam.len; k++) {
plans->resrce[j].nam[k] = nam.arr[k];
}
plans->resrce[j].nam[k] = 0;
for (k = 0; k < dscr.len; k++) {
plans->resrce[j].dscr[k] = dscr.arr[k];
}
plans->resrce[j].dscr[k] = 0;
plans->resrce[j].class = class;
plans->resrce[j].capab = capab;
plans->resrce[j].skill = skill;
plans->resrce[j].qualf = qualf;
plans->resrce[j].quant = quant;
plans->resrce[j].cost_setup = cost_setup;
plans->resrce[j].cost_run = cost_run;
plans->resrce[j].cost_rate = cost_rate;
plans->resrce[j].setup_time = setup_time;
plans->resrce[j].usage_time = usage_time;
plans->resrce[j].avail = avail;
}
end_read:
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL CLOSE C2;
printf(" successful\n");
return(NO_ERROR);
err_read:
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL CLOSE C2;
return(ERROR);
}
int db_read_resrce_rel(plans)
PLAN_DATA *plans;
{
int i;
int j;
printf("Extracting from table resrce_rel ...");
EXEC SQL WHENEVER SQLERROR GOTO err_read;
EXEC SQL DECLARE C3 CURSOR FOR
SELECT * FROM RESRCE_REL;
EXEC SQL OPEN C3;
EXEC SQL WHENEVER NOT FOUND GOTO end_read;
for(i = 0; ; i++){
EXEC SQL FETCH C3 INTO
:id,
:cnst_01,:cnst_02,:cnst_03,:cnst_04,:cnst_05,
:cnst_06,:cnst_07,:cnst_08,:cnst_09,:cnst_10,:cnst_cnt;
printf(" %d", i);
j = ++plans->ptr_resrce_rel;
plans->resrce_rel[j].id = id;
plans->resrce_rel[j].cnst[0] = cnst_01;
plans->resrce_rel[j].cnst[1] = cnst_02;
plans->resrce_rel[j].cnst[2] = cnst_03;
plans->resrce_rel[j].cnst[3] = cnst_04;
plans->resrce_rel[j].cnst[4] = cnst_05;
plans->resrce_rel[j].cnst[5] = cnst_06;
plans->resrce_rel[j].cnst[6] = cnst_07;
plans->resrce_rel[j].cnst[7] = cnst_08;
plans->resrce_rel[j].cnst[8] = cnst_09;
plans->resrce_rel[j].cnst[9] = cnst_10;
plans->resrce_rel[j].cnst_cnt = cnst_cnt;
}
end_read:
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL CLOSE C3;
printf(" successful\n");
return(NO_ERROR);
err_read:
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL CLOSE C3;
return(ERROR);
}
int db_read_prt_dat(plans)
PLAN_DATA *plans;
{
int i;
int j;
int k;
printf("Extracting from table prt_dat ...");
EXEC SQL WHENEVER SQLERROR GOTO err_read;
EXEC SQL DECLARE C4 CURSOR FOR
SELECT * FROM PRT_DAT;
EXEC SQL OPEN C4;
EXEC SQL WHENEVER NOT FOUND GOTO end_read;
for(i = 0; ; i++){
EXEC SQL FETCH C4 INTO
:id,:nam,:dscr,:factory,:db_key,:modf_idx,:unit_m,:s_t_stat;
printf(" %d", i);
j = ++plans->ptr_prt_dat;
plans->prt_dat[j].id = id;
for (k = 0; k < nam.len; k++) {
plans->prt_dat[j].nam[k] = nam.arr[k];
}
plans->prt_dat[j].nam[k] = 0;
for (k = 0; k < dscr.len; k++) {
plans->prt_dat[j].dscr[k] = dscr.arr[k];
}
plans->prt_dat[j].dscr[k] = 0;
plans->prt_dat[j].factory = factory;
plans->prt_dat[j].db_key = db_key;
plans->prt_dat[j].modf_idx = modf_idx;
plans->prt_dat[j].unit_m = unit_m;
plans->prt_dat[j].s_t_stat = s_t_stat;
}
end_read:
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL CLOSE C4;
printf(" successful\n");
return(NO_ERROR);
err_read:
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL CLOSE C4;
return(ERROR);
}
int db_read_prt_cntn(plans)
PLAN_DATA *plans;
{
int i;
int j;
printf("Extracting from table prt_cntn ...");
EXEC SQL WHENEVER SQLERROR GOTO err_read;
EXEC SQL DECLARE C5 CURSOR FOR
SELECT * FROM PRT_CNTN;
EXEC SQL OPEN C5;
EXEC SQL WHENEVER NOT FOUND GOTO end_read;
for(i = 0; ; i++){
EXEC SQL FETCH C5 INTO
:id,:s_t_consumer,:s_t_supplier,:consumer_num,:relat_fct;
printf(" %d", i);
j = ++plans->ptr_prt_cntn;
plans->prt_cntn[j].id = id;
plans->prt_cntn[j].s_t_consumer = s_t_consumer;
plans->prt_cntn[j].s_t_supplier = s_t_supplier;
plans->prt_cntn[j].consumer_num = consumer_num;
plans->prt_cntn[j].relat_fct = relat_fct;
}
end_read:
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL CLOSE C5;
printf(" successful\n");
return(NO_ERROR);
err_read:
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL CLOSE C5;
return(ERROR);
}
int db_read_proc_dscr(plans)
PLAN_DATA *plans;
{
int i;
int j;
int k;
printf("Extracting from table proc_dscr ...");
EXEC SQL WHENEVER SQLERROR GOTO err_read;
EXEC SQL DECLARE C6 CURSOR FOR
SELECT * FROM PROC_DSCR;
EXEC SQL OPEN C6;
EXEC SQL WHENEVER NOT FOUND GOTO end_read;
for(i = 0; ; i++){
EXEC SQL FETCH C6 INTO
:id,:id_s_t,:id_assoc,:dscr,:cap_grp,
:resrce_01,:resrce_02,:resrce_03,:resrce_04,:resrce_05,
:resrce_06,:resrce_07,:resrce_08,:resrce_09,:resrce_10,
:res_cnt,:est_time_run,:est_time_setup,
:rank,:usage_capacity,:req_capacity;
printf(" %d", i);
j = ++plans->ptr_proc_dscr;
plans->proc_dscr[j].id = id;
plans->proc_dscr[j].id_s_t = id_s_t;
plans->proc_dscr[j].id_assoc = id_assoc;
for (k = 0; k < dscr.len; k++) {
plans->proc_dscr[j].dscr[k] = dscr.arr[k];
}
plans->proc_dscr[j].dscr[k] = 0;
plans->proc_dscr[j].cap_grp = cap_grp;
plans->proc_dscr[j].resrce[0] = resrce_01;
plans->proc_dscr[j].resrce[1] = resrce_02;
plans->proc_dscr[j].resrce[2] = resrce_03;
plans->proc_dscr[j].resrce[3] = resrce_04;
plans->proc_dscr[j].resrce[4] = resrce_05;
plans->proc_dscr[j].resrce[5] = resrce_06;
plans->proc_dscr[j].resrce[6] = resrce_07;
plans->proc_dscr[j].resrce[7] = resrce_08;
plans->proc_dscr[j].resrce[8] = resrce_09;
plans->proc_dscr[j].resrce[9] = resrce_10;
plans->proc_dscr[j].res_cnt = res_cnt;
plans->proc_dscr[j].est_time_run = est_time_run;
plans->proc_dscr[j].est_time_setup = est_time_setup;
plans->proc_dscr[j].rank = rank;
plans->proc_dscr[j].usage_capacity = usage_capacity;
plans->proc_dscr[j].req_capacity = req_capacity;
}
end_read:
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL CLOSE C6;
printf(" successful\n");
return(NO_ERROR);
err_read:
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL CLOSE C6;
return(ERROR);
}
int db_read_super_task(plans)
PLAN_DATA *plans;
{
int i;
int j;
int k;
printf("Extracting from table super_task ...");
EXEC SQL WHENEVER SQLERROR GOTO err_read;
EXEC SQL DECLARE C7 CURSOR FOR
SELECT * FROM SUPER_TASK;
EXEC SQL OPEN C7;
EXEC SQL WHENEVER NOT FOUND GOTO end_read;
for(i = 0; ; i++){
EXEC SQL FETCH C7 INTO
:id,:dscr,:plan_level,:lot_min,:lot_siz,:avg_stock,:scrap_rate;
printf(" %d", i);
j = ++plans->ptr_super_task;
plans->super_task[j].id = id;
for (k = 0; k < dscr.len; k++) {
plans->super_task[j].dscr[k]= dscr.arr[k];
}
plans->super_task[j].dscr[k]= 0;
plans->super_task[j].plan_level = plan_level;
plans->super_task[j].lot_min = lot_min;
plans->super_task[j].lot_siz = lot_siz;
plans->super_task[j].avg_stock = avg_stock;
plans->super_task[j].scrap_rate = scrap_rate;
}
end_read:
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL CLOSE C7;
printf(" successful\n");
return(NO_ERROR);
err_read:
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL CLOSE C7;
return(ERROR);
}
int db_read_proc_cntn(plans)
PLAN_DATA *plans;
{
int i;
int j;
printf("Extracting from table proc_cntn ...");
EXEC SQL WHENEVER SQLERROR GOTO err_read;
EXEC SQL DECLARE C8 CURSOR FOR
SELECT * FROM PROC_CNTN;
EXEC SQL OPEN C8;
EXEC SQL WHENEVER NOT FOUND GOTO end_read;
for(i = 0; ; i++){
EXEC SQL FETCH C8 INTO
:id,:s_t_consumer,:s_t_supplier,:min_lead_time,:relat_quant;
printf(" %d", i);
j = ++plans->ptr_proc_cntn;
plans->proc_cntn[j].id = id;
plans->proc_cntn[j].s_t_consumer = s_t_consumer;
plans->proc_cntn[j].s_t_supplier = s_t_supplier;
plans->proc_cntn[j].min_lead_time = min_lead_time;
plans->proc_cntn[j].relat_quant = relat_quant;
}
end_read:
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL CLOSE C8;
printf(" successful\n");
return(NO_ERROR);
err_read:
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL CLOSE C8;
return(ERROR);
}