Jack, H., “http://claymore.engineer.gvsu.edu”, a presentation at the Michigan Teachers of Mechanics Conference, GVSU, April 1997.
http://claymore.engineer.gvsu.edu
Hugh Jack, Padnos School of Engineering, Grand Valley State University, Grand Rapids, Michigan, jackh@gvsu.edu
OVERVIEW:
CURRENT USE - Courses to date
A WEB SITE - The main point for all courses
WEB BASED NOTES - How to use the web to present notes
WEB BASED LECTURES - How to use the web to present in lectures
STATICS - A statics course with examples of notes, photographs, movies, working model
KINEMATICS AND DYNAMICS - A machine design course with working model and mathcad support
STUDENT PAGES - Examples of student work
PAPERLESS MARKING - The marking procedure
DEVELOPING WEB PAGES - The general procedure
WHERE NEXT - Futuristic ideas
CONCLUSIONS - Final comments
CURRENT USE - Courses to date
EGR 209 - Statics and Mechanics of Materials (Fall 1996)
EGR 352 - Kinematics and Dynamics of Machines (Winter 1996)
EGR 367 - Manufacturing Processes (Winter 1996)
EGR 450 - Manufacturing Controls (Summer 1997)
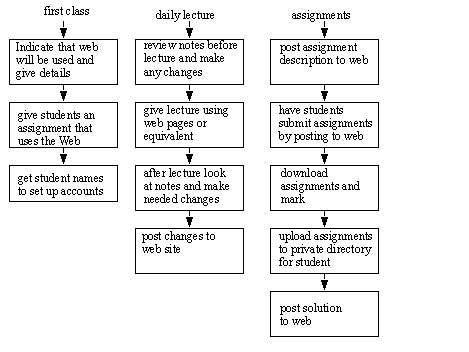
A WEB SITE - The main point for all courses
• The main point for students to go for information
• Each course has it’s own location
• Set up server
WEB BASED NOTES - How to use the web to present in lectures
• Divide into clear topics
• A directory structure will help organize materials - link up eod_directory
• Set up a strategy for each topic - mine is,
1. Some overview that sets the reason and objective for the section. (a good place for pictures)
2. An overview of relevant theory.
3. A simple example problem - with solution and notes about steps, notations, etc.
4. A simple unsolved drill problem.
5. Additional notes on technique and methods. (working model files work well here)
6. An advanced problem with solution
7. An unsolved complex problem, done on the board
• A table of contents is a good place to start - link up html table of contents page
WEB BASED LECTURES - How to use the web to present materials
• The lecture is basically conducted by the notes.
STATICS - A statics course with examples of notes, photographs, movies, working model
• Notes for all course materials
• Links to other sites
• Photographs
• Working Models
• Movies - link to Tacoma narrows bridge
KINEMATICS AND DYNAMICS - A machine design course with working model and mathcad support
• Basic note set
• Working model examples
• Mathcad Examples
• Complete design and simulation - gears
• paperless marking
STUDENT PAGES - Examples of student work
• Students can maintain own pages - link to student page
• Allows students to add to course
PAPERLESS MARKING - The marking procedure
• Download student submission
• Mark up file
• Record mark
• Upload file to private student directory
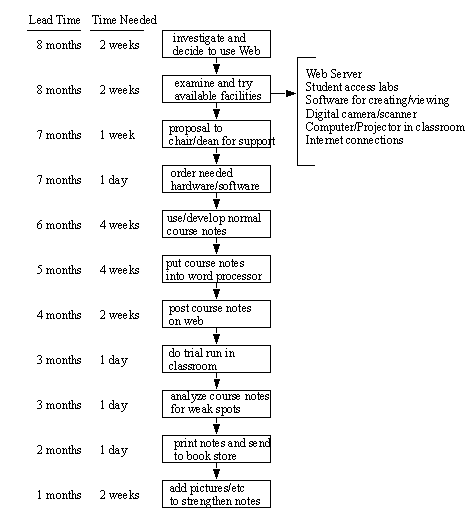
DEVELOPING WEB PAGES - The general procedure
• Start with Notes
LINK TO FRAMEMAKER DOCS
• Set up Web Site
LINK TO MAIN WEB PAGE
• Convert to Web Pages
• Add Media
WHERE NEXT - Futuristic ideas
• Course notes on CD only
• Students bring laptops and edit notes directly
• Multiple sets of course notes for different learning styles
• Special Java applets that can be embedded in course notes
CONCLUSIONS
• Good results, development will continue
• Other courses already done this way
• Paperless classroom