Jack, H., Buchal, R.O., “An Automated Workcell for Teaching and Research”, The Western Journal for Graduate Research, Vol.3, Issue 1, 1991.
AN AUTOMATED WORKCELL FOR TEACHING AND RESEARCH
by H.Jack, and R.O.Buchal of The University of Western Ontario
ABSTRACT:
Current manufacturing systems are progressing toward higher levels of integration with computers. A high level of integration will allow products to be manufactured automatically. For example, if customized keytags were to be mass produced, an integrated workcell could be used. The workcell could use a robot to load raw material into an NC Milling machine. A computer could direct the NC Machine to cut the customized keytag. When this is complete, the robot could unload the NC machine and the process would begin again.
High levels of integration are only possible when sophisticated manufacturing system architectures are used. An application using sophisticated engineering workstations for workcell control has been developed. This application was performed to provide a workcell for both teaching and research purposes.
This paper describes the application and the major design points; in particular, the different devices, the software modules, and two applications.
KEY WORDS:
CAD (Computer Aided Design), CAM (Computer Aided Manufacturing), CIM (Computer Integrated Manufacturing), Robot, NC (Numerical Control), Workstation, Workcell.
Note: Many technical terms in this paper are described in glossary.
INTRODUCTION:
As complexity increases in manufacturing systems, so does the need to integrate. Modern manufacturing systems have the ability to operate independently, and automatically. These benefits do not come without cost, such as, the fact that manufacturing tasks take longer to plan and set up.
Even though computers have been used as a basis for the CAD/CAM/CIM (refer to glossary) revolution, they are presently under-utilized. Workcells are subject to unnecessary downtime when implementing new tasks. Costs increase as production downtime increases; hence the objective is to create a workcell architecture that minimizes downtime. By implementing a proper software architecture that links all the devices in the workcell, it is possible to develop an efficient system. Reconfiguration to develop new tasks for different applications can be accomplished off-line thereby saving valuable time.
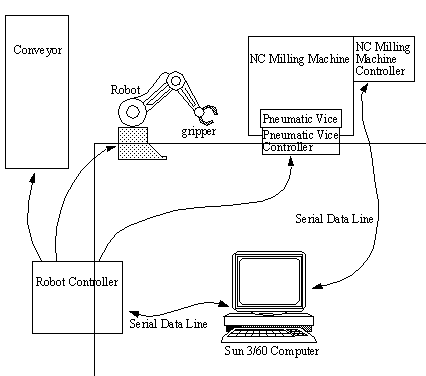
FIGURE 1 Diagram of the UWO Workcell (Top View)
The UWO CIM Cell in the Department of Mechanical Engineering consists of several basic manufacturing devices (robot, NC - Numerically Controlled - milling machine, conveyor, and pneumatic vice). These devices were used as the basis for an integrated workcell. The hub for the workcell was a Sun™ Workstation (a computer based on the UNIX operating system). The applications were developed with the following objectives:
• to produce a system that can be reconfigured rapidly (i.e., change the operation and methods),
• to allow access to all levels of workcell control for teaching and research,
• to produce a system which is easy to use by technical personnel.
This has been done by creating a clear hierarchy of functions in the workcell.
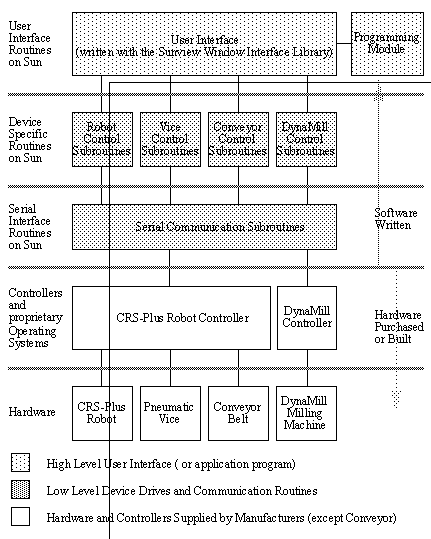
The robot and NC (Numerical Control) machine both have controllers built into them. These controllers take care of the low level control (such as motor control) through command interpretation. Unfortunately, these controllers were designed for use with an interactive user, and therefore they do not lend themselves to ‘hands-off’ automation. The pneumatic vice and conveyor are controlled through the robot controller.
The low level controllers communicate with a Sun Workstation by serial communication lines (RS-232). Thus, the lowest level software routines are for serial communication with the controllers in the workcell. The set of routines which call these communication subroutines are specific to the controllers. These routines use generic function names to generate commands for the robot controller, and to transfer NC programs. The basic set of drivers (software subroutines) promote rapid access to any workcell function without requiring a great deal of knowledge and effort from the user.
Above this, a mouse-driven user interface/programming system has been written. Since the intent was to devise an easy-to-use system, the user interface is mouse-driven. At this level the workcell is easily controlled and programmed.
In general, the approach is similar to one at New York University (NYU) [Ashley, 1990]. Divisions are drawn between five different levels of control: machine applications, control applications, planning applications, languages, and a graphical user interface. In spite of the similarities, the NYU system has disadvantages since it is based on the use of a highly specialized operating system (called Mosaic). By using a non-standard operating system, the system has reduced portability and standardization.
The remainder of this paper will be divided into discussions of the various components of the workcell, and their integration through software.
FIGURE 2 Block Diagram of Software and Hardware
An Aside on The Advantages of Automation:
Major world economic powers are turning to automation to ensure economic success. For example, Japan had the largest total of 142,850 robots as of December 1988, as compared to the second largest total of 28,500 robots in the U.S.A.[British Robot Association, 1989] This use of automation is one of many reasons why Japan’s economy has a tremendous growth rate [Blumenthal, 1990].
While many argue that automation has drawbacks, like job loss, there are many advantages. Robots tend to displace workers from dangerous and tedious jobs into positions requiring more intelligence. As for job loss, Blumenthal [1990] states, “Macro data show that, in spite of the much larger number of industrial robots in Japan, overall unemployment figures are smaller.”
THE ROBOT:
A light industrial robot was used in this integration (a CRS-Plus). The robot has five degrees of freedom. Three of the five degrees position the robot in the workspace, and the other two are responsible for orientation of the gripper (see glossary and Figure 1).
The robot controller is self-contained, and performs all major robot functions. A ‘BASIC’ like language (called RAPL) is used by the controller. It is possible to use the controller in stand-alone mode (only connected to a terminal). This preferred mode of operation is unfortunate because it forces the controlling program to “pretend” that it is a user typing instructions and reading the responses. Other than the awkward mode of communication, the robot is fairly simple to control.
The basic command types include:
• open/close gripper,
• move (relative or absolute),
• report position of arm,
• done (calibrate),
• approach/depart a goal (along the gripper axis),
• allow manual control through a hand held remote.
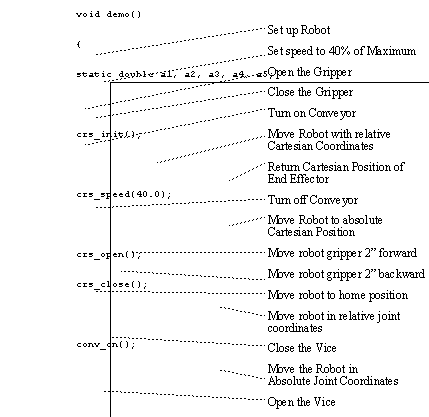
These functions are available from the robot controller, and are made accessible to the user through function calls. The user is also able to specify the robot position in joint angles (i.e., base rotation angles, shoulder rotation, etc.), or as a point in cartesian space. A list of a sample program for the robot is shown below.
FIGURE 3 List of Robot Control Program With Vice and Conveyor
THE PNEUMATIC VICE:
The pneumatic vice is used to position and hold a workpiece. The vice is controlled by a solenoid-activated pneumatic valve, connected to a shop air supply. The vice control signal is obtained from a digital output on the CRS-Robot controller; thus, to control the vice, a command is sent to the robot controller.
THE CONVEYOR BELT:
A conveyor belt is used when a workpiece must be moved a long distance. The control for this device is also done via the robot controller. When an electrical signal is received, it will close a relay which supplies power to the conveyor motor.
THE NC MILLING MACHINE:
Metal removal (for example cutting) is the goal of many popular manufacturing processes. An NC (Numerically Controlled) milling machine can be automated to cut materials. The UWO CIM Cell has a DynaMite 2400 endmill. The workpiece is fixed to a moving bed. By moving the bed and adjusting the tool height, a 2 1/2 dimension shape may be cut (refer to glossary).
The Dyna Mill controller has two modes of operation:
1. Stand-alone operation, with programs entered directly into the controller by the operator, and,
2. Off-line programming, where programs are downloaded from an external computer. In this mode a complete program can be downloaded before execution, or program instructions can be downloaded and executed one instruction at a time.
.
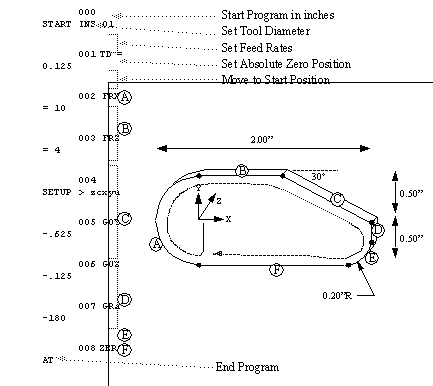
Unfortunately, when executing single instructions, the number of commands available is reduced. This complicates tasks such as cutting circular sections.
FIGURE 4 An Example of an NC Program
Another problem with the mill is that it requires an operator to manually set up the mill on the controller before it will communicate with the computer. As a result, a fully automatic start-up is not possible.
The computer routines for the NC machine are concerned with:
• downloading an NC program from a disk file to the Mill,
• uploading an NC program from the Mill to a disk file,
• sending one instruction to the mill and checking for errors.
There are many commercial software packages that can automatically generate NC code from a graphical database of the part to be manufactured. One such package is SMARTCAM (produced by Point Control Corporation). This software automatically creates a listing of the proper feed rates, speed and tool paths necessary for producing the part. All of these operations are done from a simple graphical drawing of the part. Figure 5 shows the device drivers developed to upload and download NC code files into the DYNA Mill 2400.
FIGURE 5 Function Calls for the NC Milling Machine
THE WORKSTATION:
Current trends have resulted in low cost computers which have many of the same features as mainframes, like the Sun 3/60 used here. This machine is based on the UNIX operating system, and is capable of multi-user access, multi-tasking and networking. These features allow the workcell to be run from remote computers, or from more than one program at once, or by more than one user at once.
This workstation has two (RS232) serial ports. These were used for the communicating with the robot and NC Milling Machine controllers. Each serial port may be controlled from a separate program. This makes it possible to perform tasks with either sequential, or parallel programs. The advantage of parallel programs is their ability to overcome speed barriers of computers by dividing tasks. Sequential programs may be hard to construct when two different tasks have to be done.
Some advantages of a Sun Workstation as compared to an IBM PC are;
• They are faster computers (for calculation and execution of programs).
• The graphics displays are faster, and larger.
• The UNIX operating system is very powerful.
In comparison, some of the disadvantages of a Sun workstation to an IBM PC are;
• The cost can be much higher.
• A high level of expertise is required to maintain the system.
• Memory size is unlimited
Despite the drawbacks, workstations are becoming essential. This is because many powerful programs cannot be supported with IBM PC’s.
USER INTERFACE - BASIC CONTROL:
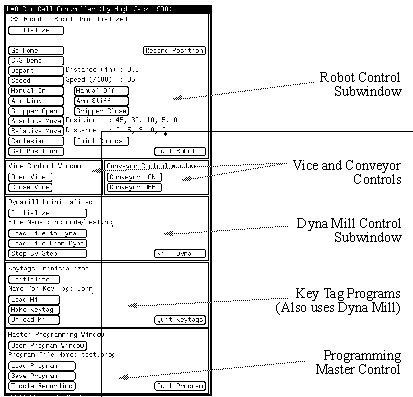
The user interface was developed so that a windowing environment could be utilized. The user can operate any device in the workcell by simply pointing and pressing a mouse button (see Figure 6).
The control of these devices has been partitioned into sub-windows for each of the major devices.
FIGURE 6 The User Interface Window (Note: The remainder of the screen not shown)
In each sub-window, the robot and the NC milling machine must be initialized before the workcell can be used. The pneumatic vice and conveyor belt are initialized by the robot initialization.
As well as the mouse buttons, textual inputs are used in a few instances. For example, a text input is used when positions and distances are required for the robot. The NC subroutines require that a file name be given as the source or destination of an NC program code.
A separate demonstration program was included with the user interface. This demonstration allows a user to make keytags with various names on them. The Keytag cutting program has been included for demonstration purposes. It will generate the NC code for the NC machine to cut customized keytags. The user is responsible for loading and unloading the vice on the milling machine. Once the part is in the vice, the user can direct the Keytag subroutine to move the vice into place, cut the part, then move the vice back to the loading/unloading position.
FIGURE 7 User Interface with Communication Window
All of the communications to the robot and NC machine are reported in the text window (see Figure 7). This allows observation of the low level activities in the workcell. The user may also receive messages and prompts through this window. Using a text window maintains a distinction between the commands and operations.
USER INTERFACE - PROGRAMMING:
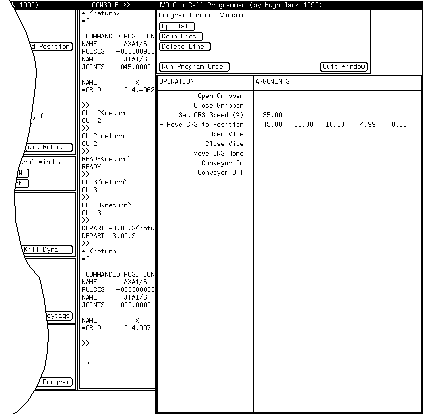
To enhance the abilities of the workcell, a programming method was devised. Programming functions are available at the bottom sub-window of the user interface (Figure 6). This sub-window will load or save a program to a file and can also call up a programming window (see Figure 8).
FIGURE 8 Workcell Programming Window
When the programming window is instructed to record, it remembers operations conducted in the workcell. The operations not automatically recorded include positions, manual control of robot, etc. When a position for the robot is to be remembered, a button in the robot sub-window must be used. This allows the user to adjust robot positions without recording the adjustments.
As can be seen, a list of commands is given in the right hand window of Figure 8. The user can scroll through these, delete operations, and append new operations by recording. Features for Inserting Lines, and for Editing Lines are not included. Any change to a workcell program could easily lead to a catastrophic collision in the workcell (accidents are very costly). Until complete simulation facilities are available, these utilities will not be implemented. Simulation would allow a user to modify a few lines of a program, then verify the changes with simulation.
AN APPLICATION OF PARALLEL PROCESSING TO THE WORKCELL
An application was developed (with a user interface) in the workcell to use the multi-processing capabilities of the Sun Workstation. The first task involved using the robot to swap three pegs between four holes. The second task was to cut customized keytags with the NC Milling machine (see Figure 9).
One program was written (using the device drivers) for control of the robot. This program included instructions on how to:
• swap pegs,
• get raw plastic blocks from a feeder,
• load the vice,
• unload the vice, and,
• put parts on the conveyor, and move them out of the workcell.
The program was very easy to write but it required knowledge of timing for milling machine loading and unloading.
Keytags were produced by a second program. This program was responsible for:
• moving the vice from the cutting to the loading position,
• moving loading to the cutting position,
• cutting the keytags.
NC code was produced, and directly sent to the Dyna Mill. This program needed to know when the robot program had loaded and unloaded the vice.
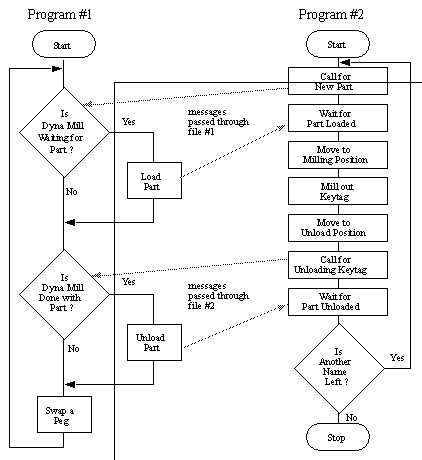
Communication between two separate programs was achieved through the use of common message exchange files. While operating, the Keytag program will write into a file when it needs a block of plastic. It will then wait until the robot has loaded the block. The robot program periodically scans the file to see if a block is needed. The same scenario happens when the milling machine is finished and needs to be unloaded. Files are very inefficient for real applications, but were sufficient for demonstration purposes. The reader may be interested that the Sun Workstations offer utilities called ‘sockets’. These take advantage of facilities in UNIX for passing messages between programs. Sockets could be used in a more sophisticated application and would replace the use of files for message passing.
The names to be cut on the keytags are pulled from a batch file. When running in this mode the programs execute successfully, without pause, and require no user interaction after start-up.
FIGURE 9 PROCESS INTERLOCK DIAGRAM
(Program #1 will continuously swap pegs, until the Milling machine needs to be loaded, or unloaded. The milling machine will make Keytags until it runs out of names)
CONCLUSIONS:
This software architecture proved to be very successful. Applications have been generated in a few hours, whereas our experience indicates similar applications would require weeks, if standard methods were used. A common approach to programming this workcell would involve writing separate programs in the proprietary language of the robot controller, and the Dyna Mill. A set of electrical connections would also have to be made for communication between the programs.
Workcell control may be easily done from one or more programs on the same computer (the Sun 3/60). No additional electrical connections are required, and knowledge of the robot and Dyna Mill have been abstracted to a high level language (i.e., C). Since control has been abstracted, it is possible to generate lab and project work.
• Small projects can be assigned for any level of control for any device. This is because students may use existing support software (and do not have to produce their own).
• Larger projects may be built in a modular fashion, and replace existing modules one at a time.
• Use of the same computer allows the students to become familiar with one working environment using sophisticated software debuggers and editors. This also eliminates complex communication problems between programs.
• Projects may be created using graphics which were not possible before.
• Introductory laboratories may be done using the graphical interface. These would introduce the concepts, before the details are explored.
Alternately, research has a slightly different set of objectives. Research requires that control and data collection be removed to a higher level. The main reason for using the workstation for control is because of the computing power. Modern research into parallel computation, real-time data collection and analysis, expert systems, etc. all require computation power which is not available on smaller machines. The only other alternative is a mainframe system which would have significantly higher costs. This is not acceptable if the research is to have any value to industry.
The objectives of this research have been met, although there are some general observations which must be made:
• Workcell devices should allow a completely automatic start-up. In this case the CRS-Plus robot and the Dyna 2400 Milling machine require manual initialization.
• Workcell devices should allow a remote control of all functions and modes. This is so that the user is not forced to push buttons and the computer does not have to mimic a terminal user.
• Any workcell device should either i) not prompt the user until the present command is complete, or, ii) report when a command is complete. This would help alleviate timing problems. It was necessary to use time delays to avoid command overlaps for the CRS-Plus robot.
• The Dyna 2400 should not use a reduced instruction set when executing immediate commands. For example, local reference coordinates do not work when executing single lines at a time.
By moving the control level of the workcell to the Sun Workstation, it is possible to create some powerful new applications. Ease of access to all control levels of the workcell was accomplished. By April of 1991, one undergraduate project should be complete. This project involves the removal of the robot control algorithms and replacement with a graphical simulation. This will allow the use of all high level software, but with a graphical simulation instead of the workcell. Advantages of simulation are that actions may be checked for safety before execution, the programs can be checked while the workcell is being used, and they allow rapid evaluation of relocated devices in the workcell. Parallel control of the workcell has also been realized. Some undergraduate (and graduate) projects which are now possible are:
• a graphical simulation of the complete workcell,
• an APT to Dyna 2400 NC code translator,
• a graphical simulation of NC code, and the shapes that are cut,
• addition of new devices to the workcell. This includes vision, sensors, feeders, rotary tables, buffers, robots, etc.,
• parallel processing across the network (between two or more Sun computers) for multiple cell control,
• new programs to generate NC code for custom parts. Some student projects design geometry for gears, but do not generate the NC code for their manufacture.
• development language for control of the workcell.
• use of novel technologies, like petri nets [Kaddour and Courvoisier, 1987], which may be used for scheduling various manufacturing jobs for the same workcell.
REFERENCES:
Ashley, S. 1990. A Mosaic for Machine Tools. In Mechanical Engineering, pp. 38-43.
Blumenthal, T. 1990. Economic effects of robotization in Japan. In Robotics and Autonomous Systems. Vol.6, No. 4, pp. 323-326.
British Robot Association 1989. Annual Report of UK Investment in Robot Automation in Manufacturing Industry. In Robotics and Autonomous Systems, Vol.5, No. 3, pp. 289-292.
Dyna Electronics Corporation 1987. DM2400/2200 Programming Manual, California, U.S.A.
CRS Plus Inc. 1987. Small Industrial Robot System Technical Manual, Ontario, Canada.
Kaddour, N. O., and Courvoisier, M. 1987. Issues for Concurrent Programming in Real-Time Systems. In Proceedings 1987 IEEE International Conference on Robotics and Automation, pp. 1469-1474.
GLOSSARY:
2 1/2 Dimensions - A shape that can be described in terms of position and height. A shape of this sort can be machined from above only (i.e., a ball is not 2 1/2 D while a hemi-sphere is).
CAD - Computer Aided Design is the use of computers to model the geometrical, and manufacturing properties of a product.
CAM - Computer Aided Manufacturing involves the use of computer automated machinery to make parts, and products.
CIM - Computer Integrated Manufacturing is the use of computers to pull all levels of manufacturing together, also including sales, production, marketing and management.
Conveyor - A moving belt upon which work pieces move into, or out of the work cell.
End Effector - used interchangeably with ‘Gripper’.
End Mill - A machine which machines in 2 1/2 dimensions. In this case the milling machine can cut downward from a number of positions, but not from the bottom or sides of the part.
Gripper - A device mounted at the end of a robot arm for grasping work pieces or tools.
NC - Numerically Controlled machines use simple programs to direct their operations. An example is seen in this paper.
Pneumatic Vice - An air controlled vice for holding a part during work. When a pressurized air supply is applied, pressure is applied to the workpiece.
Robot - A device which can be programmed for moving parts and tools.
Serial Communication - Transmits data in a scheme like the old teletype machines, one bit at a time. RS 232 is an international standard for serial communication.
Window - An area of a computer display, which is used for organizing functions. By pointing into a window, the user may select a function with the mouse buttons.
Workcell - A collection of automated machines for performing manufacturing operations.
Workstation - Usually a small computer with powerful graphics abilities (based on microprocessors) which has many abilities of larger computers.
RECOMMENDED READING:
Groover, M.P. 1987. Automation, Production Systems, and Computer Integrated Manufacturing. New Jersey, U.S.A.