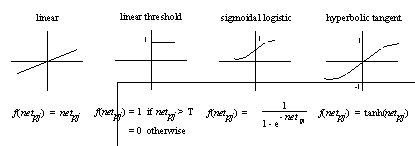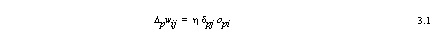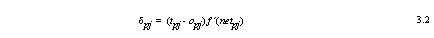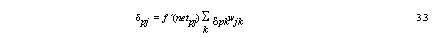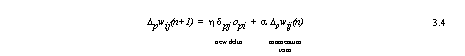CHAPTER 3 - ARTIFICIAL NEURAL NETWORKS
3.1 Introduction:
Artificial neural networks are based on approximate models of the brain. The basic building block of an artificial neural network is the neuron. The brain in made up of about 100 billion neurons, with an average of 1,000 to 100,000 input connections per neuron. When many of these neurons are combined they have the properties of a massively parallel super-computer.
In multi-layer neural nets (as used in this thesis), each neuron is connected to other neurons via a weighted communication line. The weights of the connections are adjusted in training to represent the knowledge of the neural network. One method for adjusting these weights is with a training algorithm.
Neural networks are good when dealing with abstract problems, like those based on features and patterns. Artificial neural networks are mainly used in two areas: feature detection and pattern mapping.
Feature detection is done by classifying an unknown input pattern, by comparison to previously learned patterns. This ability is termed associative recall. An example of this is the use of neural networks to recognize handwritten digits [Guyon et. al., 1989]. In pattern recognition, when a particular pattern is noisy or distorted, the network can generalize and choose the closest match [Guyon, 1989][Guyon et. al., 1989][Byte, 1989][Reber and Lyman, 1987].
In pattern mapping, continuous input patterns are presented to the neural network in order to evoke continuous output patterns. An example is the use of a neural network as a basic controller in a manufacturing control system. The controller would accept important operating and system conditions as the inputs, and a set of control outputs would drive the current process [Psaltis et. al., 1987].
Thorough reviews of neural networks are available in several references [Lippman, 1987][Byte, 1989][Rummelhart et. al., 1986][Wasserman, 1988]. These references are both introductory and advanced. This thesis will be primarily concerned with one neural network paradigm commonly called feed-forward neural networks. The learning algorithm is Backpropogation [Rummelhart et. al., 1986].
3.2 Advantages of Feed Forward Neural Networks:
Neural networks are a new way of performing complex tasks. They have several properties which are advantageous. Marko and Feldkamp [1990] show the power of neural networks to solve very complex problem. They use the neural network to diagnose engine faults on a production line.
The advantages of neural networks are quite apparent, in particular a list of advantages might be made for feed forward neural networks.
• Feed forward neural networks have a fixed computation time,
• Computation Speed is very high, as a result of the parallel structure,
• Fault tolerant [Moore, 1988], because of distributed nature of network knowledge,
• Learns general solutions of presented training data,
• Neural networks eliminate the need to develop an explicit model of a process.
• Neural networks can model parts of a process that cannot be modelled or are unidentified.
• If an explicit mathematical model is not required, then the network can be ‘programmed’ in a fraction of the time required for traditional development.
• A neural network can learn from noisy and incomplete data [Guez and Selinsky, 1988a, 1988b][Troudet and Merril, 1989], the solution will just be less precise. (as seen in the maximum torque chapter, later)
• Ability to generalize to situations not taught to network previously.
• Can be taught to compensate for system changes from initial training model (on-line).
3.3 Disadvantages of Feed Forward Neural Networks:
Like any technique, neural networks have certain drawbacks. Most of the shortcomings are based upon the current state of the art.
• Since the NN finds a general approximation of a solution, there is a small error usually associated with all the NN outputs.
• The full nature of Neural Networks is still not fully understood, and thus current research must take an experimental approach to the problem of performance.
• At present, there are not any NN computers available at a reasonable cost.
• Neural networks errors vary, depending upon the architecture.
• Neural networks require lengthy training times.
Neural networks provide the best results when used to complement current computing techniques, which contain poorly defined problems. The current computing schemes can handle well defined problems, and the neural networks can deal with the unmodelled problems.
3.4 An Artificial Neuron:
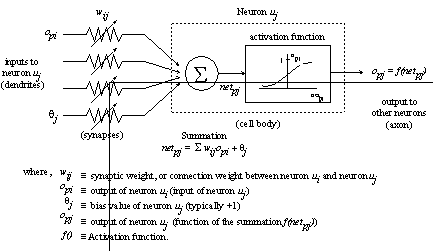
An artificial neuron is a simple non-linear combiner. The figure below shows the structure of a basic artificial neuron.
.
Figure 3.1: Basic structure of an artificial neuron.
When operating within a neural network, the neuron, uj, receives inputs (opi) from previous neurons (ui) while the network is exposed to the input pattern p. Each input (opi) is multiplied by the connection weight, wij, where wij is the connection weight between neurons ui and uj. The connection weights correspond to the strength of the influence of each of the preceding neurons. After the inputs have been multiplied by the respective input weights, their resulting values are summed, and an activation function is applied to the summed value. This activation level becomes the neuron’s output and can be either an input for other neurons, or an output for the neural network.
The θj in the summation, netpj, in the figure is a bias value. The bias value acts as a type of level shifter. It increases or decreases the summation by a constant, finite amount so that a neuron may cover an offset input range. In order to establish the correct bias value θj, the bias term may appear as an input from a separate neuron with a fixed value (usually an input neuron with a constant output value of +1). The bias’ connection weights are then adjusted with the other weights as the network learns.
The advantage of using such an element for computation is a valid question. A single neuron can simulate 14 of the 16 boolean functions. It cannot emulate the X-OR, or the X-NOR gates [Minsky and Papert, 1969]. This is because a single neuron can only deal with problems that have linearly separable solution sets. The real power of artificial neural networks comes as a result of having many neurons connected in layers. When multi-layer networks are used, all sixteen of the basic boolean functions may be emulated.
The power of the neurons becomes more evident when using the analogy of basic logic gates. Consider that any of the basic logic gates may be constructed of neurons. Any computer can be constructed out of millions of basic gates. The human brain has 100,000 time more circuitry than a computer. Therefore, the brain has a computational ability which is orders of magnitude higher than current computers.
3.5 Neuron Activation Functions:
A real neuron has a certain response to input stimulation. This response tends to take a non-linear form, with limits. When dealing with artificial neurons, this function must be approximated.
In the artificial neuron, the netpj value in the neuron is processed by an activation function and becomes the output of the neuron. The activation function may appear in many forms.
Figure 3.2: Common Activation Functions.
The simplest transfer function is linear. This is the activation function used in the original perceptrons. Linear functions do not take advantage of multi-layer networks, thus, a non-linearity is usually desired. A linear threshold function is simple non-linear activation function, in which the output of the neuron is +1 if a threshold level is reached and 0 otherwise. Other functions tend to limit the continuous output of the neuron between a maximum and minimum value. The advantage of using such functions is that very small and very large summations (netpj) can still be processed. And, the neuron can operate over a wide range of input levels. Hyperbolic tangents and the sigmoidal logistics are more similar to real neuron responses, except the hyperbolic tangent is unbounded and hard to implement in hardware.
3.6 Neural Network Architectures:
Neurons are rather arbitrary units that may be connected in numerous ways. With feed forward networks, there is always an input layer of neurons, and subsequent, progressive layers leading to the output layer. Note that the inputs are forward propagated, and later in this chapter it will be seen that output errors may be backward propagated for network learning.
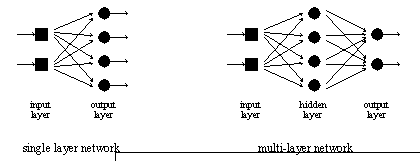
The circular nodes in figure 3.3 represent the basic processing neurons. The input neurons are shown as squares because they only act as input terminal points (i.e., opi = neuron input). The circular nodes represent neurons that process information, that is, the inputs are summed and sent through an activation function. An output neuron is the connection to the outside world.
Figure 3.3: Simple Feedforward Artificial Neural Networks
A Single layer network consists of a single layer of input neurons, and a layer of output neurons. The properties of the network are those of single neurons. A single layer network can effectively map many sets of inputs to particular outputs. A multi-layer network consists of an input layer of neurons, one or more hidden layers, and an output layer. Neurons which are not directly accessible to the outside world are called hidden neurons. It has been shown that with enough neurons in the hidden layer any continuous function may be learned [Lippman, 1987].
Note that the bias values for the neurons are not shown here, but this is because it can just be another input with a constant real value (e.g., +1).
3.7 The Backpropagation Learning Algorithm:
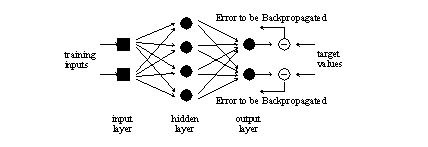
The backpropagation learning algorithm was made widely popular by Rummelhart et. al. [1986]. Learning with backpropagation consists of determining the proper set of connection weights to estimate a given training set. A training set consists of expected outputs for specific inputs. The learning process involves i) solving the network for a set of inputs, ii) comparing the outputs to the expected values, and then iii) using the errors to estimate a correction to each weight value in the network.
Figure 3.4: Backpropagation of errors.
The training process is repeated iteratively until the network has closely matched its outputs with the training set. This is known as convergence. A trained network will have the property of generalization. This property may be evaluated by testing the network with a data set which is similar, but non-intersecting with the training set. If the results for the test set are the same as with the training set, then the network may be said to have generalized. If the network has converged, but has not generalized, then the network may be said to have memorized the training set. If the network generalizes, then it should be able to handle any problem that is similar to the training set.
The back propagation learning rule is simply a gradient descent algorithm. It minimizes the squares of the differences between the actual and desired outputs, summed over the output neurons for all training examples. The initial state in the network has a random set of connection weights. This is because, when a system starts with all connection weights being equal, the network begins at a type of local optimum, and will not converge.
The rule for modifying the connection weights for a single neuron is called the delta rule. The weights (wij) on each input should change by an amount (Δpwij) which is proportional to the error signal, δpj, and the input signal of the neuron (opi).
‘Δpwij’ represents the change that should be made to the connection weight for the link between neuron ‘ui’ and neuron ‘uj’ for the input pattern ‘p’. ‘η’ is the constant of proportionality usually called the learning rate, ‘δpj’ is the delta of neuron ‘uj’, this would just be the output error for a single neuron. ‘opi’ is output of preceding neuron ‘ui’ (or the input to neuron ‘uj’).
For a one-layered network, the change in connection weights can easily be calculated since the difference, or ‘δ’ of the output neurons is readily available (i.e., output error). With the introduction of hidden layers, the desired outputs of these hidden neurons are difficult to estimate. In order to compute the delta of a hidden neuron, the error signal from the output layer must be propagated backwards to all preceding layers. This is for influencing the modification of the connection weights leading into a hidden neuron.
The delta value for any output neuron is computed as,
where, ‘tpj’ is the desired, or target output of output neuron ‘uj’. ‘opj’ is the actual output of output neuron ‘uj’, and ‘f ´(netpj)’ is the first derivative of the activation function for the given input pattern ‘p’ evaluated at neuron ‘uj’.
For the hidden neurons, the deltas are calculated from the previously calculated deltas, found in subsequent layers. That is, the deltas found in the output layer must be propagated backwards (analogous to the forward pass of the input signals) through the connection weights so that an appropriate error signal can be estimated for each hidden neuron. The error signal, or delta, for the hidden neurons is,
where ‘f ´(netpj)’ is the first derivative of the activation function with respect to the total output (netpj) evaluated at hidden neuron ‘uj’. ‘δpk’ is the delta value for the subsequent neuron ‘uk’. ‘wjk’ is the connection weight for the link between hidden neuron ‘uj’ and subsequent neuron ‘uk’. ‘δpj’ is the delta for hidden neuron ‘uj’.
3.8 Summary of Methods:
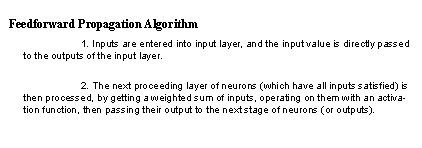
For forward propagation of inputs (to produce outputs), the network follows these stages, in a simple algorithm.
The training algorithm is a little more complex, and uses the previous algorithm. One cycle of the training algorithm is shown in the algorithm below.
This algorithm is repeated until the network achieves a satisfactory degree convergence.
3.9 The Modified Delta Rule:
When training a network, the selection of the learning, and smoothing rates is important. These rates affect how the network moves through weight space. In order to obtain the correct connection weights for the problem at hand, the backpropagation (gradient descent) approach requires steps be taken in weight space. If the steps are too large, then the weights will overshoot their optimum values. If the steps are too small, they can become caught in local optimum. The step size must therefore be scaled as a function of the learning rate. The learning rate, η, should be large enough to come up with a solution in a reasonable amount of time, without having the solution oscillate within weight space.
By introducing a momentum term, the learning rate can be increased while preventing oscillation. The momentum term filters high frequency variations in weight space characterized by ravines with sharp curvatures. The momentum term is introduced by adding to the weight change some percentage of the last weight change.
where ‘η’ is the learning rate varying between (0, 1), ‘α’ is the momentum term between (0, 1). ‘Δpwij(n+1)’ is the weight change in the current training interval for pattern ‘p’, and ‘Δwij(n)’ is the weight change in the previous training interval.
This modified delta rule is discussed in [Rummelhart, 1986], it is used as a direct replacement for the other delta rule.